训练大语言模型的计算挑战 (Computational challenges of training LLMs)
训练大型语言模型(LLM)时面临的计算挑战可以分为以下几个主要方面:
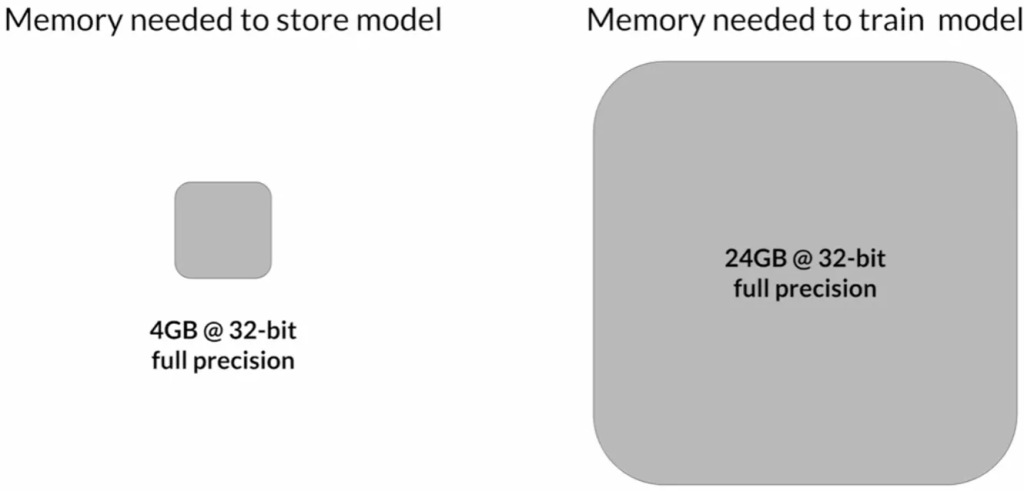
内存需求: 大型语言模型因其庞大的参数数量而需要大量内存。一个参数通常由32位浮点数表示,占用4字节内存。例如,存储十亿个参数需要4GB的GPU内存。在训练过程中,除了模型权重外,还需要为优化器状态、梯度、激活函数和临时变量分配内存。因此,实际上训练一个十亿参数的模型可能需要约24GB的GPU内存。
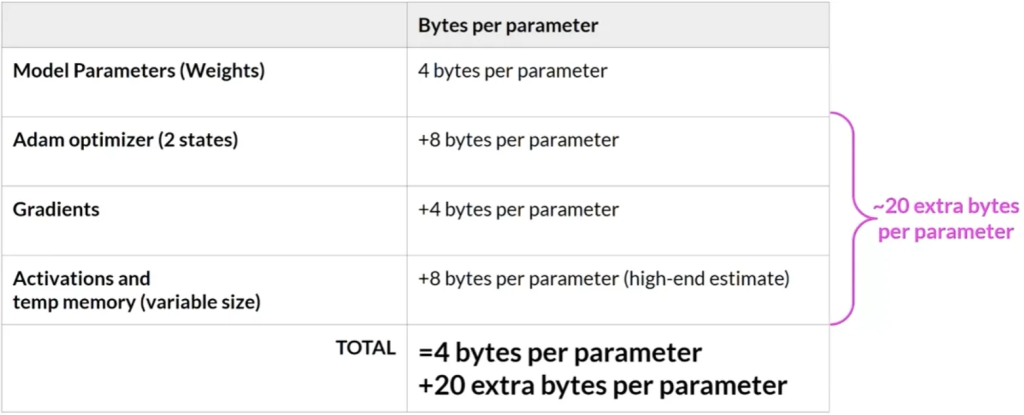
量化: 为减少训练所需的内存,可以采用量化技术。量化通过降低参数的位数来减少内存需求,例如将32位浮点数转换为16位(FP16)或8位(int8)的表示。这样,原始的32位浮点数被映射到更低精度的空间中。例如,FP16只需要2字节的内存,而int8只需1字节。但是,量化会导致精度的损失。
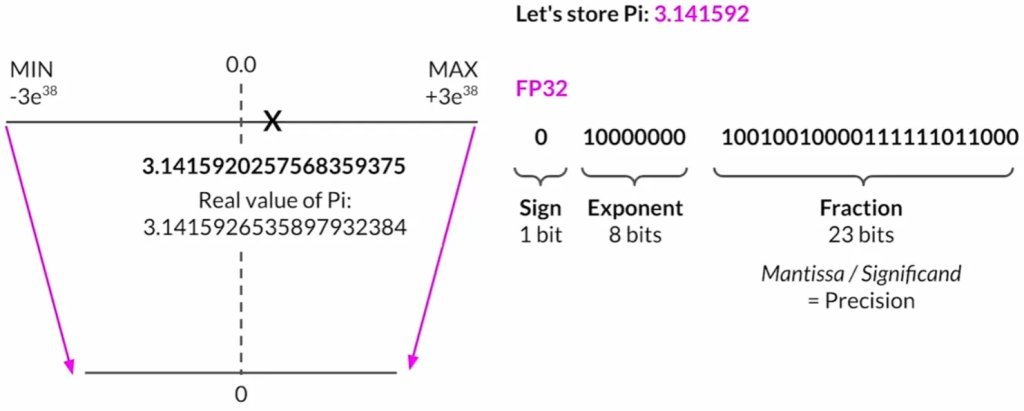
Quantization: FP32
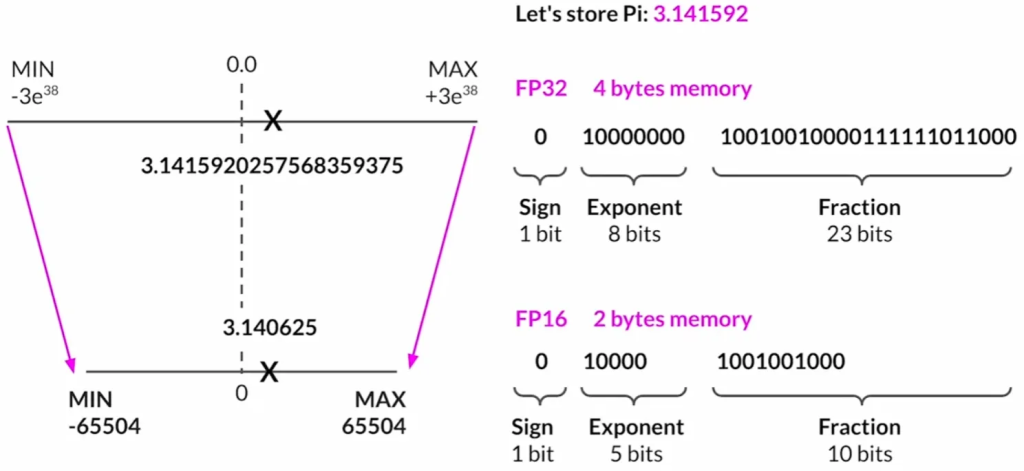
Quantization: FP16
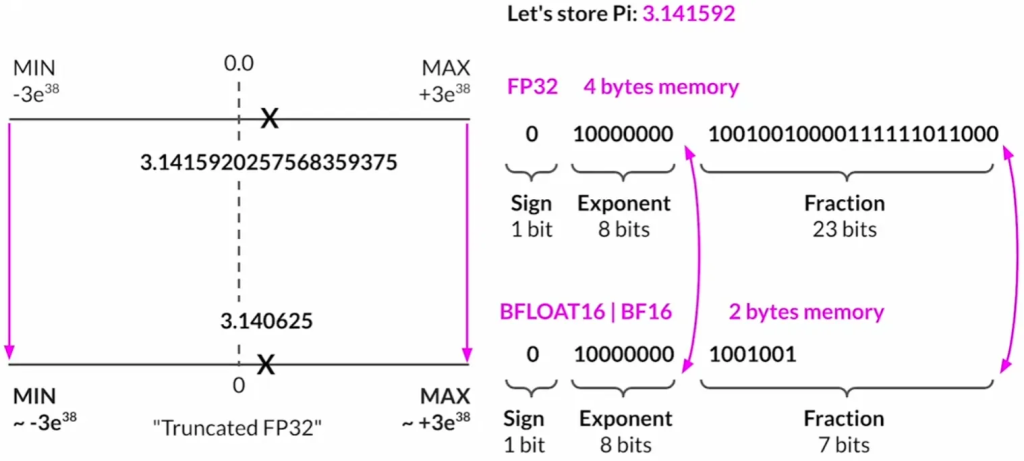
Quantization: BFLOAT16
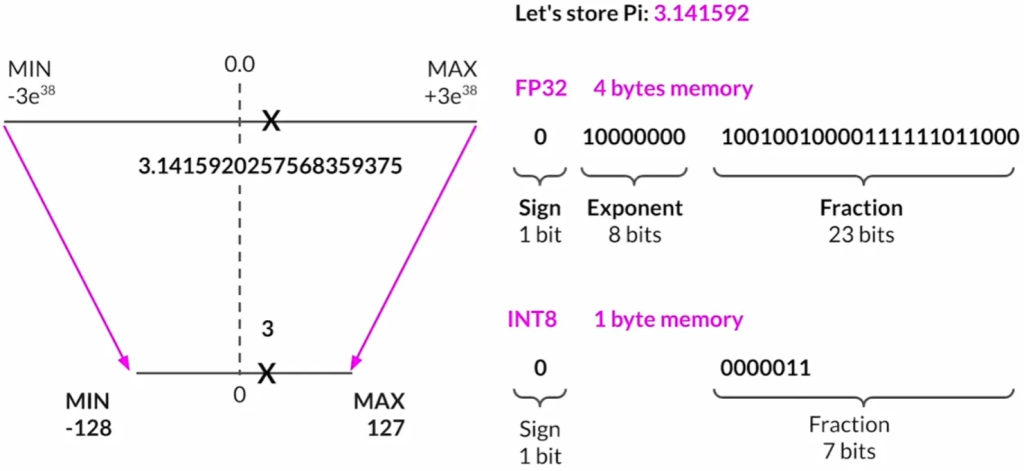
Quantization:INT8
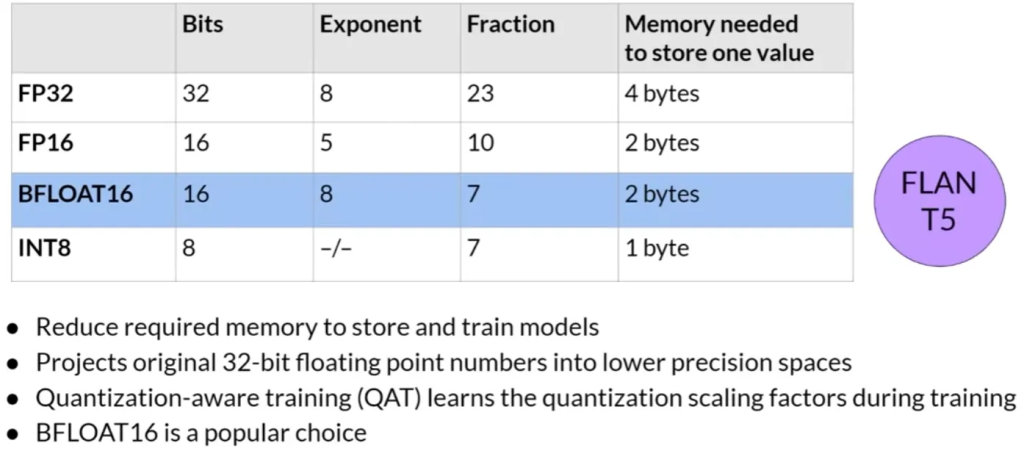
Quantization:Summary
模型大小和可扩展性: 随着模型大小的增加,单个GPU变得不足以处理训练任务。例如,50亿或100亿参数的模型需要更多的内存,远远超出单个GPU的能力。这导致了对分布式计算技术的需求,即在多个GPU上进行模型训练。
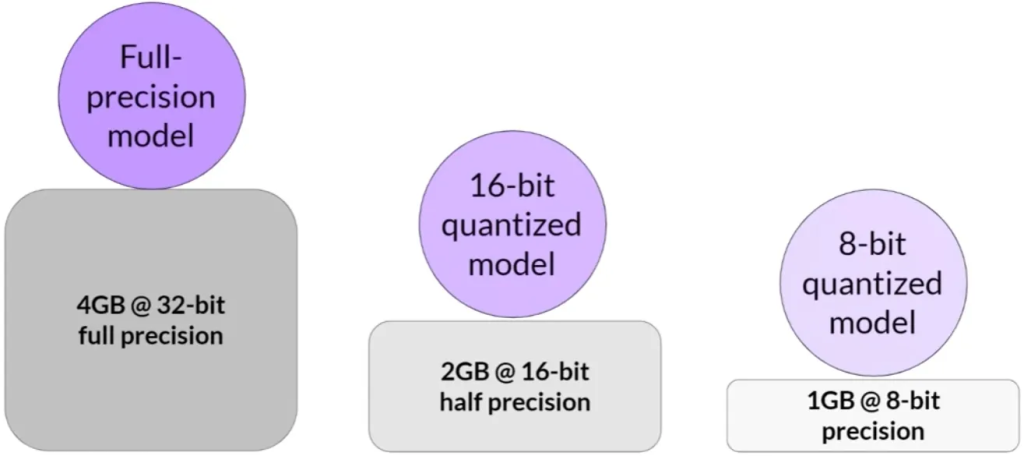
Approximate GPU RAM needed to store 1B parameters

GPU RAM needed to train larger models
分布式训练: 分布式训练涉及在多个GPU上训练模型,以克服单GPU内存限制。这通常涉及到昂贵的硬件资源,例如需要成百上千的GPU来进行训练。
微调: 即使在微调阶段,也需要在内存中存储所有训练参数,这增加了对内存的需求。微调是一个额外的训练过程,可以提高模型在特定任务上的性能。
训练大型语言模型是一个资源密集型的过程,需要大量的内存和计算能力。通过技术如量化可以在一定程度上减少内存需求,但随着模型大小的增长,单个GPU变得不足以处理任务,需要转向更复杂且成本更高的分布式计算解决方案。