Computational challenges of training LLMs
大型语言模型(LLM)训练过程涉及多种计算挑战,主要包括内存限制、数据量大、计算资源需求高等方面。以下是对这些挑战的详细解释和总结:
- 内存限制:
- 训练大型模型时最常见的问题之一是内存不足。LLM由于其巨大的规模,需要大量内存来存储和训练所有参数。
- 一个32位浮点数(通常用来表示一个参数)占用4字节的内存。因此,存储10亿个参数需要4GB的GPU内存。
- 在训练期间,除了模型权重外,还需额外内存存储如 Adam 优化器状态、梯度、激活函数和临时变量等。
- 训练中大约需要模型权重内存的20倍,意味着训练一个10亿参数模型需要大约80GB的GPU内存。
- 量化技术:
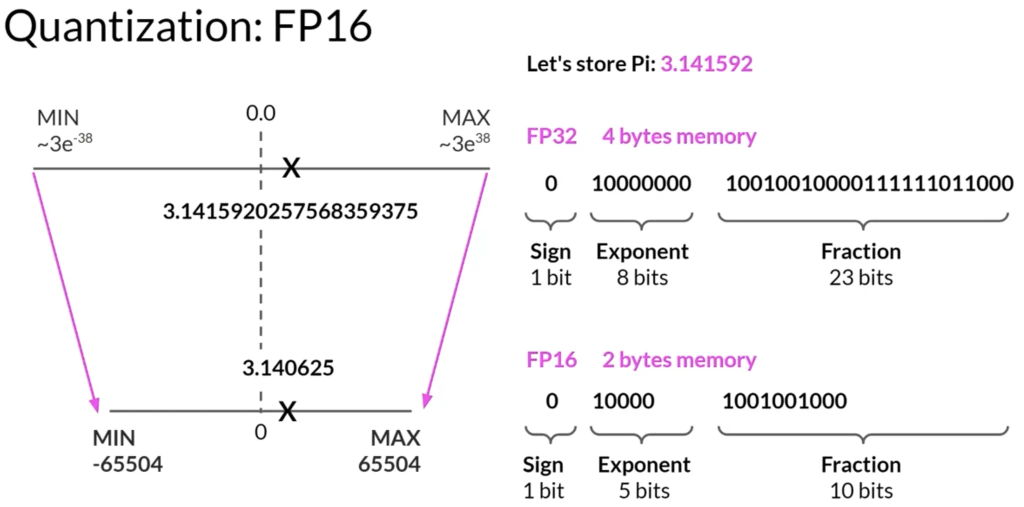
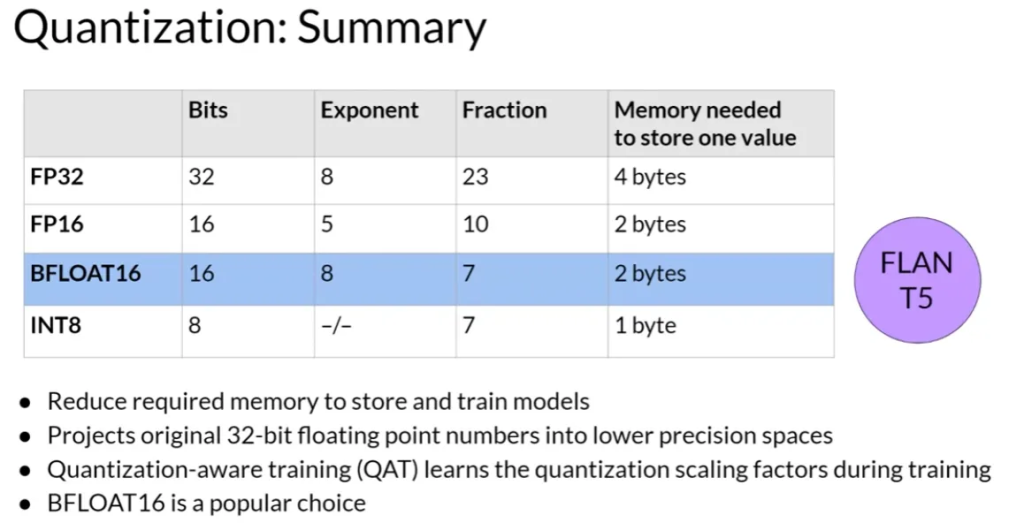
- 量化是一种减少内存需求技术,通过将模型权重从32位浮点数降低到16位浮点数或8位整数来实现。
- 使用量化后,每个值的内存需求减半或更多,从而减少模型的整体内存占用。
- 量化的影响:
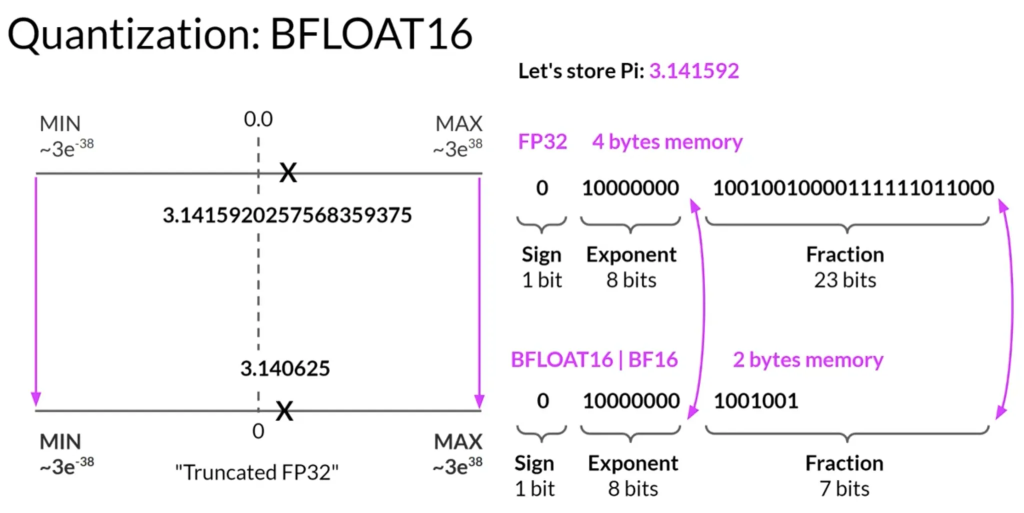
- 量化虽然减少内存需求,但可能会牺牲一定的精度。例如,将32位浮点数转换为16位,虽然节省了内存,但也减少了表示数值的精度。
- BFLOAT16是一种流行的量化选择,维持了FP32的动态范围,但内存需求减半。
- 计算资源:
- 由于大型模型的庞大规模,单一GPU往往无法满足训练需求。例如,一个10亿参数的模型在32位精度下训练,可能需要超出单个NVIDIA A100 GPU(80GB内存)的容量.
- 对于更大的模型(如超过50亿或100亿参数),所需内存容量可能高达数千GB。
- 分布式计算:
- 随着模型规模的增大,单GPU训练变得不可行,需要转向多GPU或分布式计算技术。
- 分布式训练需要访问大量的GPU,这可能非常昂贵。
- 微调过程:
- 微调(fine-tuning)也是一个重要的训练过程,它要求在内存中存储所有训练参数,通常在预训练的基础上针对特定任务进行。

总结来说,训练大型语言模型面临的计算挑战主要包括巨大的内存需求、高昂的计算资源成本以及优化这些挑战的技术需求,如量化和分布式计算。这些挑战需要开发者在资源配置、模型设计和训练策略上进行细致的规划和调整。