Efficient multi-GPU compute strategies
当模型训练规模超出单GPU能力时,采用高效的多GPU计算策略成为必要。以下是对这些策略的详细解释和总结:
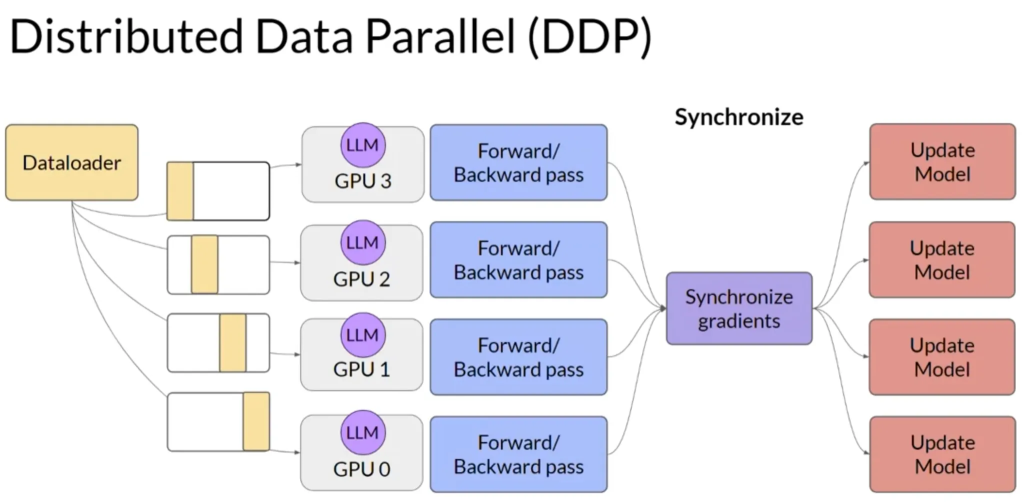
- 数据并行处理:
- 当模型能够适配于单个GPU时,可以通过在多个GPU上分布大型数据集并并行处理数据批次来扩展模型训练。
- 一个流行的实现是PyTorch的分布式数据并行(Distributed Data-Parallel,简称DDP).
- DDP将模型复制到每个GPU并并行发送数据批次。每个GPU上的数据被并行处理然后通过同步步骤合并每个GPU的结果来更新模型。
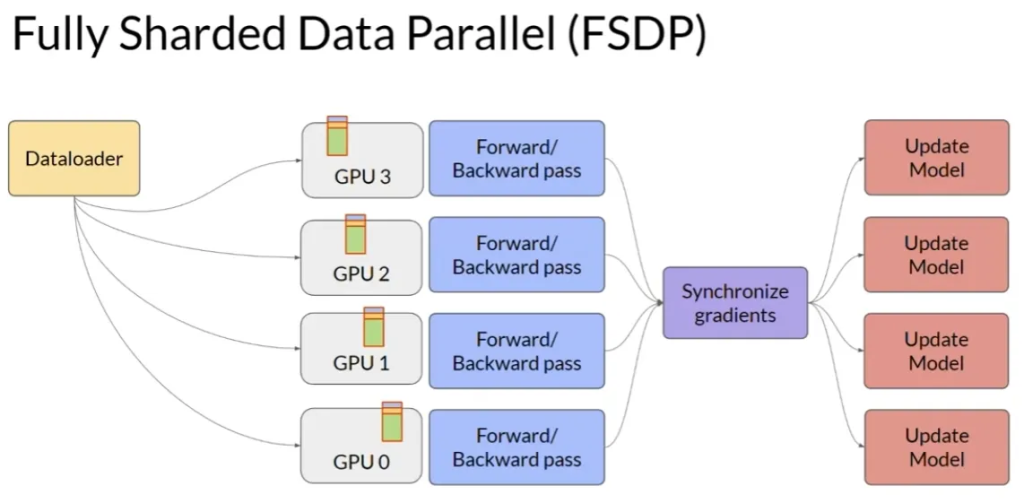
- 模型分片技术:
- 对于无法适配于单个GPU的大型模型,可以采用模型分片技术。
- PyTorch的全分片数据并行(Fully Sharded Data Parallel,简称FSDP)是模型分片的一个流行实现。
- FSDP基于Microsoft 2019年提出的ZeRO(Zero Redundancy Optimizer)技术。ZeRO通过分布(分片)模型状态到各个GPU上以优化内存。
- ZeRO的工作原理:
- ZeRO1:只在GPU间分片优化器状态,可减少内存占用高达4倍。
- ZeRO2:也在GPU间分片梯度。与阶段1一起,可以减少内存占用高达8倍。
- ZeRO3:包括模型参数在内所有组件都在GPU间分片。与前两阶段一起,内存减少与GPU数量成线性关系。
- FSDP的实现:
- 在多个GPU上分布数据,使用ZeRO策略中指定策略分片模型参数、梯度和优化器状态.
- 与DDP不同,FSDP在前向和反向传播前需要从所有GPU收集数据。
- 每个GPU在操作期间请求其他GPU上的数据以实现未分片数据,并在操作后释放非本地未分片数据。
- 性能与内存之间的权衡:
- FSDP允许通过配置分片因子来管理性能与内存使用之间的权衡。
- 分片因子为1时,相当于DDP,完全复制模型。分片因子最大时,开启全分片,节省最多内存但增加GPU间通信量。
- FSDP与DDP的性能对比:
- 使用512个A100 GPU的测试中,FSDP在不同大小的T5模型性能与DDP相比有所不同.
- 对于小模型,FSDP和DDP性能相似。但对于超大模型(如参数超过22.8亿的模型),DDP会遇到内存不足问题,而FSDP可以处理并提供更高性能。
- 随着模型增大和分布到更多GPU上,通信量增加可能会影响性能。