语义分割(Semantic Segmentation)
Semantic Segmentation 是一种更为精细的目标检测方法,它不仅可以识别图像中的对象,还能为图像中的每个像素分配一个标签,以便精确识别对象的边界和内容。

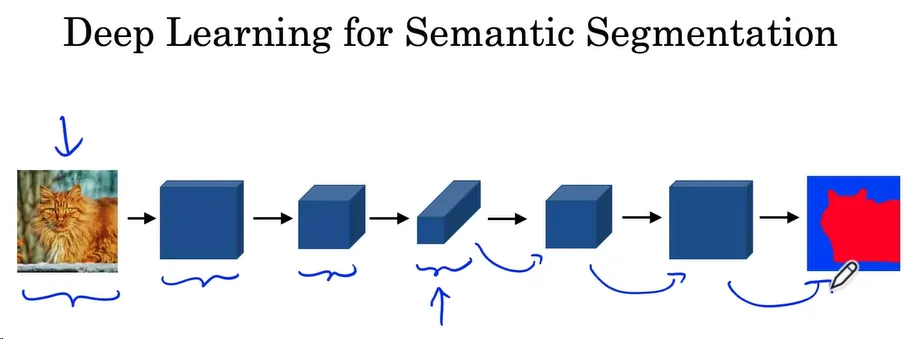
什么是语义分割(Semantic Segmentation)
在语义分割中,算法的目标是将图像中的每个像素分类到某个特定的类别,而不仅仅是识别对象并在其周围画一个边界框。可以用于精确识别目标的边界,分辨出对象的具体形状和内容。
例如,在自动驾驶领域,语义分割可以用来识别道路的边界,以便车辆能够精确地知道哪些地方是可行驶的。
语义分割的应用
- 自动驾驶: 语义分割可以用来识别道路的边界,找到可行驶的路面。
- 医疗图像处理: 语义分割可以用来识别X光或MRI图像中的不同组织和结构,帮助医生诊断疾病或规划手术。
U-Net 神经网络架构
U-Net 是一种用于语义分割的神经网络架构,它的特点是在网络的深层部分,图像的尺寸逐渐减小,*然后在浅层部分逐渐增大,最终输出一个与输入图像相同尺寸的标签矩阵。*流程如下:
- 输入图像: 将图像输入网络。
- 特征提取: 网络的深层部分提取图像的特征。
- 上采样: 在网络的浅层部分逐渐增大图像的尺寸,直到达到原始尺寸。
- 输出标签矩阵: 输出一个与输入图像相同尺寸标签矩阵,其中每个像素值对应一个类别。
在 U-Net 中,尺寸的增加是通过转置卷积(Transpose Convolution)实现的,它是一种特殊的卷积操作,能够将小尺寸的特征图上采样到更大的尺寸。
转置卷积
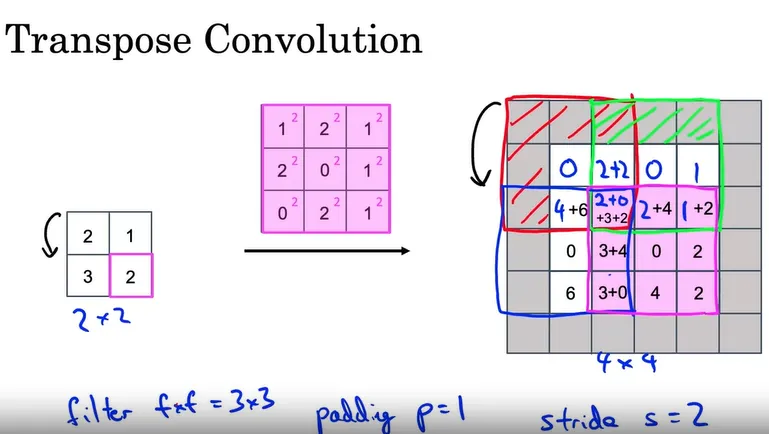
转置卷积(Transpose Convolution)是一种卷积操作,它可以将较小的输入张量(通常是由卷积层生成的特征图)扩展到更大的尺寸。转置卷积是 U-Net 神经网络结构的重要组成部分,它使得网络能够将小尺寸的特征图上采样到原始图像的尺寸,以进行语义分割。
转置卷积的工作原理
转置卷积的原理与常规卷积不同,它不将filter应用于输入图像,而是将filter应用于输出图像。
具体步骤如下:
- 选择一个滤波器(例如,3×3 的滤波器),并设定参数,如 padding 和步长 stride。
- 将输入图像的每个值乘以滤波器中的所有值,得到一个新的矩阵。
- 将新矩阵的值放入输出图像的对应位置。
- 如果有重叠的区域,将重叠区域的值相加。
- 重复上述步骤,直到处理完输入图像的所有值。
通过这种方式,转置卷积可以将小尺寸的输入图像扩展到更大的尺寸,这是在 U-Net 架构中进行语义分割的关键步骤。
示例
假设我们有一个 2×2 的输入图像:
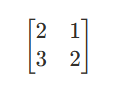
我们想将其扩展到4×4的尺寸。我们选择一个3×3的滤波器,并设定填充为1,步长为2。我们将输入图像的每个值乘以滤波器中的所有值,然后将得到的新矩阵放入输出图像的对应位置。如果有重叠的区域,我们将重叠区域的值相加。通过这种方式最终得到一个 4×4 的输出图像。
转置卷积是一种有效的方法,可以在保持图像内容的同时,将小尺寸的图像扩展到更大的尺寸.这种方法在 U-Net 架构中用于语义分割任务,使得网络能够将小尺寸的特征图上采样到原始图像的尺寸,以进行精确的分割。
总结
Semantic Segmentation 是一种精细的目标检测方法,它可以将图像中的每个像素分配到特定的类别,从而精确识别对象的边界和内容。U-Net 是一种用于语义分割的神经网络架构,它通过特殊的转置卷积操作,可以将小尺寸的特征图上采样到原始尺寸,从而输出与输入图像相同尺寸的标签矩阵。这种方法在自动驾驶、医疗图像处理等领域有广泛的应用。