单任务微调 (Fine-tuning on a single task)
单一任务微调的目的:
- 虽然大型语言模型(LLM)因能够在单一模型中执行多种语言任务而闻名,但你的应用可能只需要执行单一任务。在这种情况下,你可以对预训练模型进行微调,以提高其在特定任务上的性能。
- 例如,使用针对该任务的示例数据集进行总结。
微调所需的示例数量:

- 与预训练期间模型看到的数十亿文本片段相比,微调可以通过相对较少示例(通常只需500-1000个示例)就能达到良好的性能。
微调的潜在缺点:
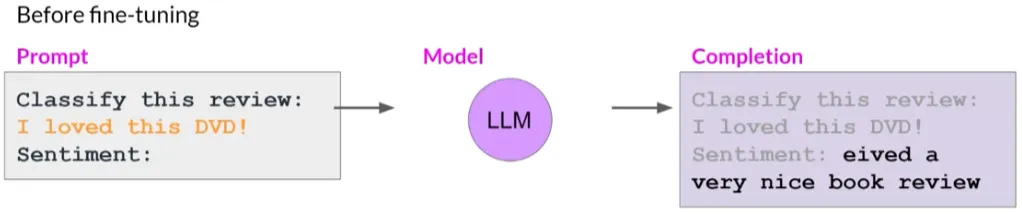
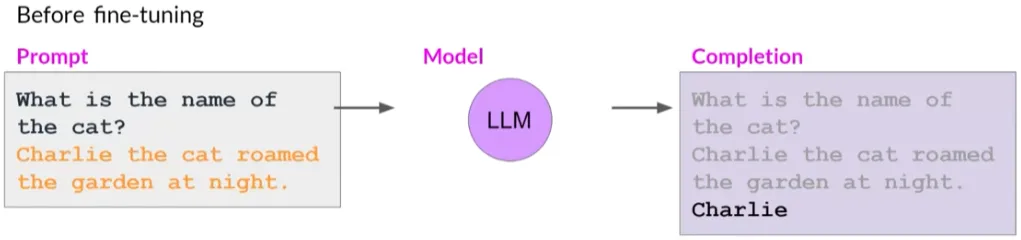

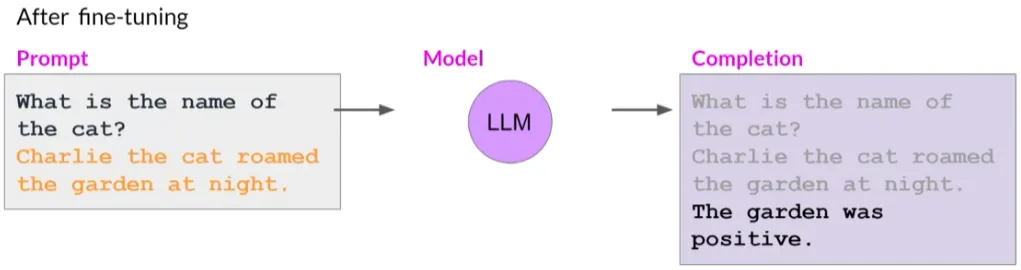
微调单一任务的潜在缺点是可能导致一种称为“灾难性遗忘”(catastrophic forgetting).
因为全量微调过程修改了原始LLM的权重。虽然这导致在单个微调任务上表现出色,但可能会降低在其他任务上的性能。
例如,微调提高模型在评论情感分析上的能力,但模型可能忘记如何执行命名实体识别
避免灾难性遗忘的方法:
- 如果只需在微调的单一任务上可靠地表现,那么模型无法泛化到其他任务可能不是问题
- 如果你希望或需要模型保持其多任务泛化能力,你可以同时对多个任务进行微调。良好的多任务微调可能需要50-100,000个示例,因此需要更多数据和计算资源来训练。
参数高效的微调:
- 作为全量微调替代,可以执行参数高效微调(Parameter Efficient Fine-Tuning,PEFT).
- PEFT是一系列技术,保留原始LLM的权重,只训练少量特定任务的适配器层和参数。
- 由于大部分预训练权重保持不变,PEFT对灾难性遗忘显示出更强的鲁棒性。
- PEFT是一个激动人心且活跃的研究领域。
在LoRA中,权重矩阵的修改是通过向原始权重矩阵添加一个低秩矩阵来实现的。这个低秩矩阵通常比原始权重矩阵小得多, 因此更新的参数数量相对较少。 这样可以有效降低对额外存储和计算资源的需求,同时允许模型在新的任务上进行有效学习。
LoRA是PEFT领域的一个重要贡献,因为它提供了一种在保留预训练模型泛化能力的同时,对模型进行特定任务调整的高效方法。这使得LoRA在处理需要对大型模型进行微调的任务时,成为一个有吸引力的选择。
针对单一任务的微调是提高特定任务性能的有效方法,但需要注意灾难性遗忘的潜在风险。为避免这种风险,你可以考虑多任务微调或参数高效的微调策略。这些策略可以帮助模型在特定任务上表现出色,同时保持对其他任务的泛化能力。