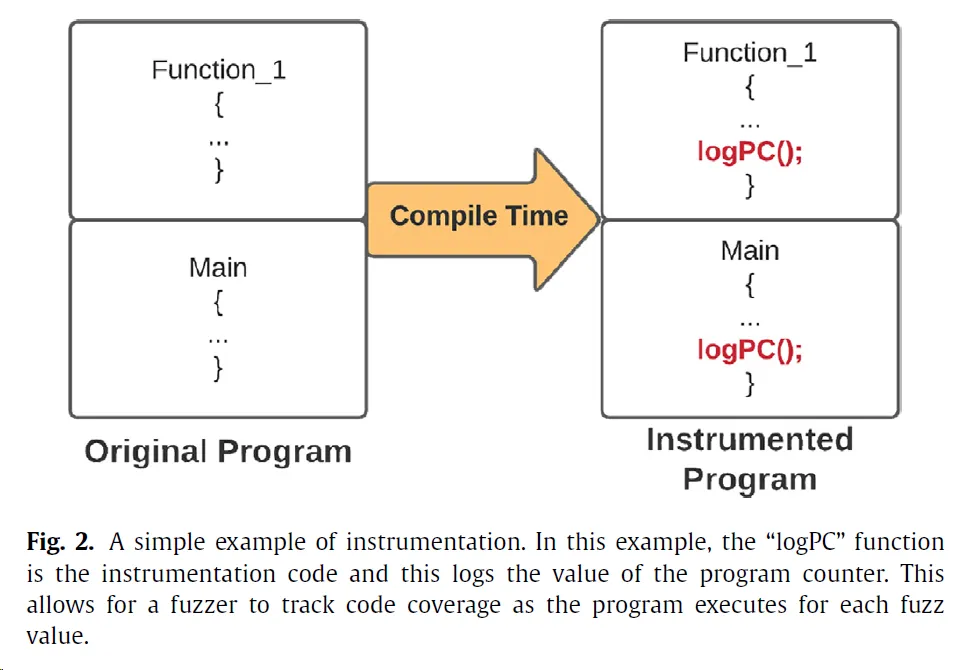
Fuzzing 调研笔记
Classification of Fuzzers
测试样例反馈(Test case feedback)
按测试用例是否根据程序的执行情况更新生成Fuzzers分为Dumb Fuzzers和Smart Fuzzers。
Dumb Fuzzers简单地选择一种测试用例生成方法并坚持使用。第1代的Fuzzers往往属于此类。
Dumb Fuzzers的优点是不特定于任何给定程序,因此可以相对容易地应用于许多不同的程序。
Dumb Fuzzers的缺点是它们的测试用例不太可能导致错误或漏洞的发现,从而增加测试时间。
尽管Dumb Fuzzers仍在使用,但研究主要集中在 Smart Fuzzers。Smart Fuzzers 会为输入做出更智能的选择,以便更好地测试特定程序。这是通过根据程序行为修改输入生成过程来实现的(李等,2018)。例如,如果注意到包含字符串“abc”的输入种子可以更深入地进入程序,则Fuzzers可能会使未来的种子更有可能包含此字符串。
对应用程序结构的了解(Knowledge of application structure)
模糊测试器(Fuzzers)按照它们对应用程序结构知识的了解程度分为三种主要类型:
- 黑盒模糊测试器:
- 无需任何关于应用程序结构的知识。
- 只关注输入和输出,不分析程序的代码执行路径。
- 白盒模糊测试器:
- 通过符号执行技术,对测试程序进行深度分析以系统地增加代码覆盖率。
- 通过分析不同输入如何影响程序状态来指导测试。
- 灰盒模糊测试器:
- 介于黑盒和白盒模糊测试器之间,可能会使用一些程序源代码或执行信息,但不如白盒模糊测试器那样全面。
- 可以利用程序分析(例如代码覆盖率信息)来指导模糊测试进度。
测试样例生成方法(Test case generation method)
模糊测试中生成测试用例的方法是非常重要的,不同的生成方法会影响到测试的效果和效率。
- 基于变异的模糊测试器 (Mutational-based fuzzers):
- 从一组初始有效输入(称为”种子”)开始,并通过变异这些输入来生成新的测试用例。
- 变异可以包括随机翻转位、重新排序输入数据的部分等。
- 基于生成的模糊测试器 (Generational-based fuzzers):
- 使用一个蓝图(例如,输入模型或语法)来从头构建有效的输入。
- 例如,如果测试程序需要一个JPG图片,基于生成的模糊测试器会按照某种配置或模型来生成有效的JPG文件。
- 随机模糊测试器 (Random fuzzers):
- 完全随机地生成测试用例,没有依据任何先前的输入或模型。
- 这种方法往往效率较低,因为随机生成的输入很可能会被测试的程序立刻拒绝。
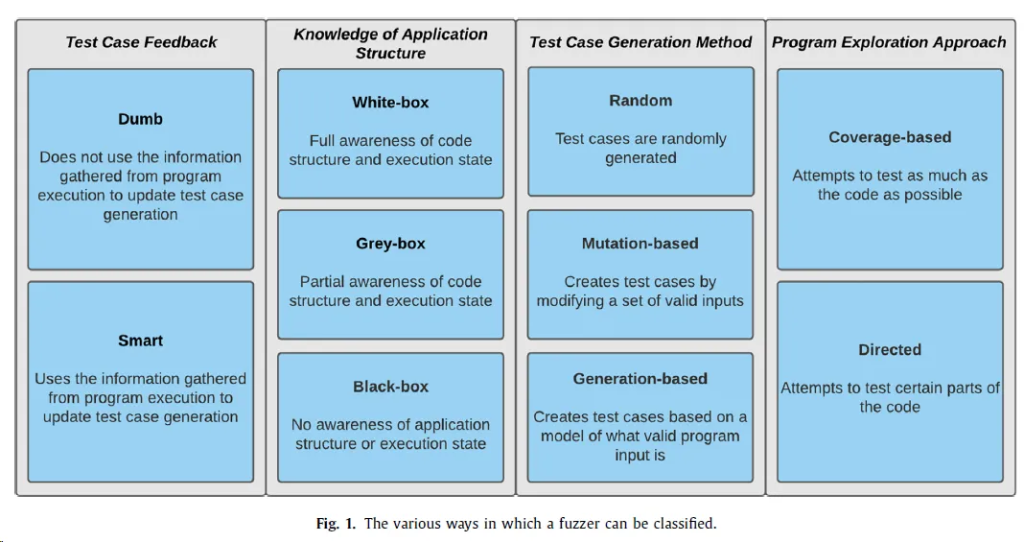
程序探索方法(Program exploration approach)
基于它们如何探索和测试程序,有两种主要的模糊测试器:
- 有目的的模糊测试器 (Directed fuzzers):
- 专注于触及程序的特定部分,生成的测试用例目标明确。
- 基于覆盖率的模糊测试器 (Coverage-based fuzzers):
- 旨在通过测试用例覆盖尽可能多的代码,提高代码覆盖率。