博弈论(研究生课程)期末作业 (2)
https://ieeexplore.ieee.org/abstract/document/8598984
1. 引言(INTRODUCTION)
1.1. 理解(Comprehension)
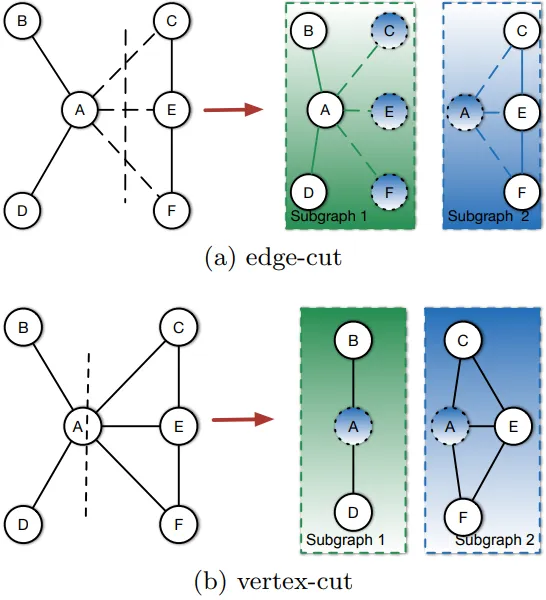
这篇论文的引言部分首先阐述了大规模图在许多实际应用中的应用,如网络图和在线社交网络。然后,它介绍了在分布式系统中进行图计算的挑战,特别是需要在机器之间划分整个图,以及图划分如何显著影响分布式图计算系统的通信成本和工作负载平衡。它还指出,现有的图划分策略可以分为顶点划分和边划分两种。
在顶点划分方案中,各个分割中的顶点是不相交的,边则跨越两个分割。在边划分方案中,边被划分到不同的分割,而顶点则跨越多个分割。此外,作者还指出,大多数真实世界的图都遵循幂律度分布,而边划分方案对于幂律图可以取得更好的性能。
然后,引言部分进一步讨论了一些现有的边划分策略的问题,如DBH和HDRF。例如,DBH总是选择度数高的顶点进行切割,这在实际的流式设置中可能行不通。HDRF使用部分度来帮助决策,但是这也可能不适用于真实的流式设置,因为在真实的流式设置中,无法提前计算全局度信息,而存储全局度表会消耗大量内存。
顶点分割和边分割的区别与联系
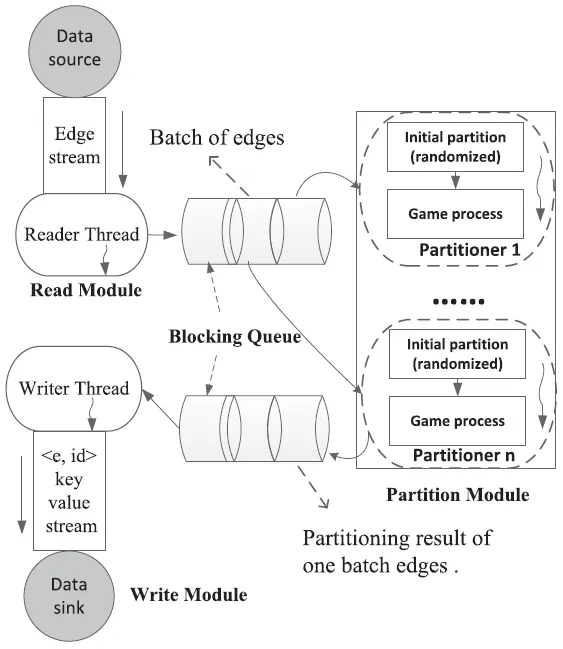
基于这些观察,作者提出了一种准流式模型和一个新的边划分策略。在这个模型中,整个边流被分成一系列的批次,每个批次的大小是输入参数。在每个批次中,所有的边构成了一个博弈过程的玩家集。每个边的划分选择被视为博弈中的理性策略。当每个批次的博弈过程达到纳什均衡,即没有边有动机单方面改变其当前的划分选择时,这个批次的划分任务就完成了。每个批次的划分任务可以由一个划分线程来完成,所有的划分线程可以并行进行。
作者指出,与流式模型和离线模型相比,他们的准流式模型的总内存消耗只是批次大小$\times$线程数,这比流式模型和离线模型的内存消耗都要小得多。此外,由于引入了并行性,准流式模型的时间消耗也可能减少。
最后,作者列出了他们的贡献,包括提出了解决边划分问题的准流式模型和基于博弈论的新型划分策略;他们数学证明了在准流式边划分博弈中纯纳什均衡的存在性,并分析了收敛到纳什均衡所需的回合数;他们证明了纳什均衡和社会最优之间的比例(即,无序性的代价,Price of Anarchy, PoA)在他们的边划分博弈中是由分割数量限制的;他们通过对大型真实世界图和随机图的综合实验评估了他们方法的性能。
准流式图分割模型
Price of Anarchy(PoA):
Price of Anarchy(PoA)是一个经济学和博弈论的概念,用于衡量在非合作博弈(也就是参与者做出的决策是为了最大化自身的利益,而不是整体的利益)中,个体理性行为可能导致的社会福利(总体效用)的损失。 具体来说,Price of Anarchy是指在一个非合作博弈中,达到纳什均衡(每个参与者都无法通过单方面改变策略来提高自己的收益)的总体效用与在全局最优(所有参与者都按照最优策略行动,以最大化总体效用)的总体效用之间的比例。 如果这个比例接近1,那么即使参与者按照自己的私人利益行动,总体效用也不会比全局最优的情况下低很多。然而,如果这个比例远小于1,那么个体的理性行为可能会导致总体效用大大降低。 在论文中,作者可能使用Price of Anarchy来衡量他们的算法在理想情况(全局最优)和实际情况(纳什均衡)之间的效用差距。这可以帮助读者理解算法的性能,并与其他算法进行比较。
在引言部分的最后,作者概述了论文的其余部分的结构,包括相关工作的介绍,系统模型和问题定义,具有理论分析的准流式边划分博弈的呈现,一个基于最佳响应动态的算法以找到纳什均衡,策略性能的评估,以及对工作的总结。
总的来说,这篇论文介绍了一种新的图划分策略,该策略基于博弈论,并利用准流式模型来解决大规模图划分问题。这种策略允许并行处理,以提高效率,并试图克服传统流式和离线图划分方法的局限性。
1.2. 翻译(Translation)
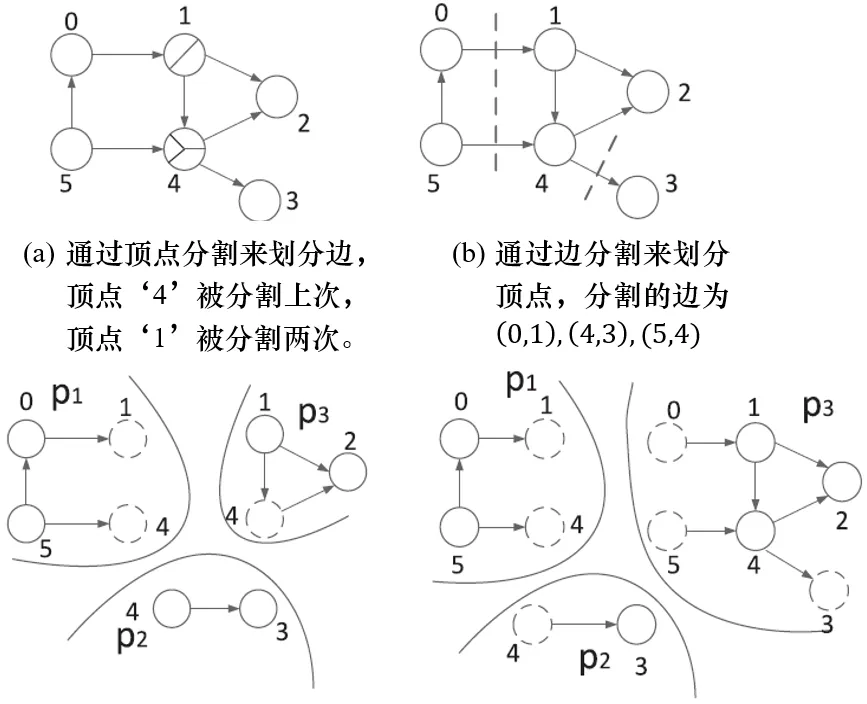
如今,大型图已经在各种真实应用中出现,如网页图和在线社交网络。从这些图中挖掘知识面临巨大挑战,因为它们的容量正在爆炸式增长。要在分布式系统上进行图计算,必须在多台机器间对整个图进行分割,这是一个必要的过程。图分割可以显著影响分布式图计算系统的性能,包括通信成本和工作负载平衡。现有的图分割策略可以分为两类:顶点分割和边分割。顶点分割导致不同分割中的顶点互不相交,边则跨越两个分割。相反,边分割导致边在不同分割中分离,顶点则跨越几个分割。顶点分割和边分割的区别在图1中有所说明。
在顶点分割方案中,每个分割的工作负载由其承载的顶点数量决定。通信成本由横跨不同分割的边的数量决定。在边分割方案中,每个分割的工作负载由其承载的边的数量决定。此外,通信成本由所有顶点的副本总数决定。顶点分割方案已被大多数分布式图计算框架采用,如Pregel[15],GraphLab[14]和Giraph[19]。
大多数真实世界的图遵循幂律度分布。已经证明,边分割方案可以为幂律图提供更好的性能[9]。因此,提出了几种基于边分割的策略,如DBH[24]和HDRF[18]。然而,DBH[24]利用全局度信息总是切割高度顶点。在真实的流处理环境中,这可能是不可行的,因为在流处理系统中,如[22],计算是连续且不间断的。至于HDRF[18],它使用部分度来帮助做出决定。它维护一个全局度表,每个顶点有部分度。当新的边到来时,两个端点的度都会更新。然而,这些解决方案在真实的流处理环境中也可能不适合。在真实的流处理环境中,无法提前计算全局度信息。此外,存储全局度表需要消耗内存,其中m是图的边的数量。对于一台商品机器来说,当图的边的数量超过一个限制时,这可能是无法接受的。
此外,在这样一个巨大的表中进行查找也可能效率低下。此外,基于流模型的现有解决方案缺乏并行性(更多细节请参见第3.1节)。例如,Stanton和Kliot[21]将并行执行流图分割视为他们的未来工作,如他们所说,“第二个方向是解决使用并行加载器…我们期望并行加载器在图流的独立部分上运行的性能…”。
基于这些观察,我们在本文中提出了一种准流模型和一种来自博弈论的新颖的边分割策略,如图2所示。在这个模型中,整个边流被划分为一系列批次,其中批次大小(一定数量的边)是一个输入参数。在每个批次中,所有的边构成了游戏过程中的玩家集合。边的分割选择被视为游戏中的理性策略。当每个批次的游戏过程达到纳什均衡,即没有边有动机单方面改变其当前的分割选择时,这个批次的分割任务就完成了。每个批次的分割任务可以由一个分割线程完成,该线程对应于图2中的分割器。所有的分割线程可以并行进行。如前所述,准流模型可能是从流模型中发现潜在并行性的一个有趣尝试[21],期望通过并行分割图流的独立部分获得类似的性能。
与流模型和离线模型相比,我们的准流模型的总内存消耗只有批次大小乘以线程数量,这比流模型和离线模型中的内存消耗都要小得多。此外,与流模型相比,由于引入了并行性,准流模型所用的时间也可能大大减少。这些理论分析在实验中也得到了证实(第6.2节)。
值得注意的是,大多数真实世界的图是通过广度优先的方式收集的[3],[25]。因此,当图被存储为边列表形式时,相同顶点的边被存储在彼此旁边。此外,大多数真实世界图的度遵循幂律分布,其中大多数顶点的度都很小。如果批次大小大于大多数顶点的度,我们可以将由每个批次组成的子图视为近似不相交的。因此,我们可以并行地对这些批次进行分割。我们需要指出,如果上述假设不成立,即如果一个顶点的边在输入中不连续出现,我们可以进行一个预处理步骤,更多的细节将在第6.2节给出。注意,准流模型的假设似乎比流模型的假设要强得多,因为在准流模型中,一个边可以根据同一批次中其他边的选择偏离其当前的分割选择(更多细节请参见第5节)。然而,在准流模型中,批次大小是分割数量的常数倍。因此,每个批次内的信息非常有限。相反,在流模型中,每条边可以通过一次通过的方式利用所有先前边的分割选择。因此,在准流模型中执行高效的分割可能比在流模型中更难。