生成式 AI 项目全流程 (Generative AI Project Lifecycle Cheat Sheet)
黎 浩然/ 25 11 月, 2023/ 大语言模型/LARGELANGUAGEMODEL/LLM, 机器学习/MACHINELEARNING, 研究生/POSTGRADUATE, 计算机/COMPUTER/ 0 comments
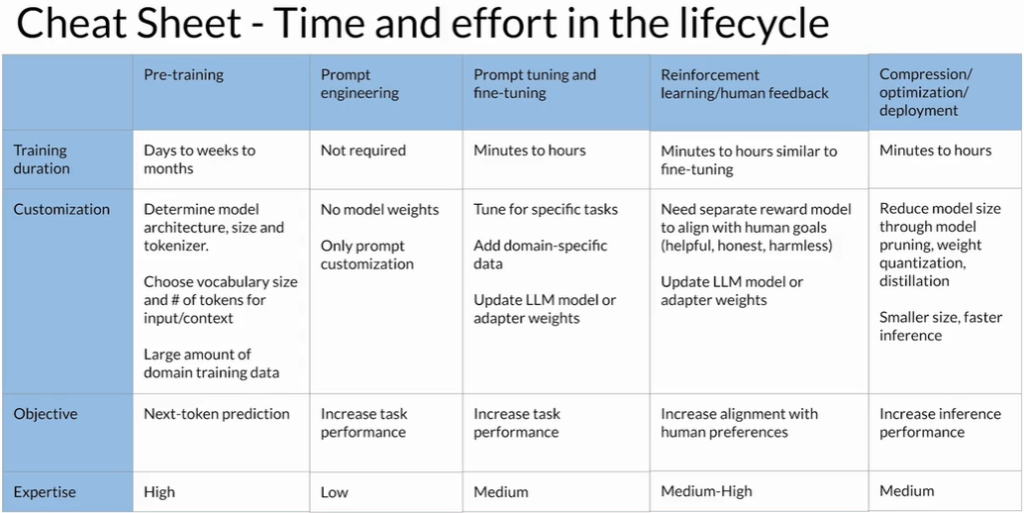
1 整体生命周期概览
| 阶段 | 主要目标 | 典型耗时 | 技术/资源要求 | 何时考虑跳过 |
|---|
| A. 预训练 (Pre-training) | 从零训练大型基础模型 | 数周-数月 | 海量数据 + 大规模算力 + 深厚模型架构经验 | 已有成熟基础模型可用时 |
| B. 提示工程 (Prompt Engineering) | 仅通过设计提示评估并提升模型表现 | 数小时-数天 | 低~中级 ML & 业务知识 | 总是值得先做 |
| C. 微调 (Fine/Prompt Tuning) | 用任务数据定制模型 | 1 天-数周 | PEFT(LoRA、Prefix/Prompt Tuning)或全参微调技术;少量标注数据即可 | 当提示工程仍不达标时 |
| D. 对齐 (RLHF/RLAIF) | 让模型符合人类偏好与安全原则 | 极快-极慢 | | |
- 现成 Reward Model:数小时
- 需自建 RM:收集人类反馈→数周-数月 | RL 框架(PPO 等)+ 反馈标注流程 | 若已有合适 RM |
| E. 部署优化 (推理加速/量化/蒸馏等) | 压缩模型、降低延迟、节省成本 | 数小时-数天 | 硬件兼容性测试 + 性能监控 | 若优化影响精度需回滚 |
2 各阶段要点与实操提示
- 预训练
- 难度最高:需决定模型规模、数据管线、分布式训练策略。
- 一般项目可跳过:直接从开源或商业基础模型开始。
- 提示工程
- 核心思路:多轮试验、Few-shot / Chain-of-Thought / System Prompt 调整。
- 低门槛:不改模型权重;适合早期快速验证可行性。
- 微调
- 方法梯度
- Prompt Tuning(软提示,极少参数)
- LoRA / IA³(对少数权重添加可训练适配器)
- 全参数微调(任务极特殊或数据量大时才用)
- 数据量:往往几百到几千条高质量样本即可显著提升。
- 预算控制:PEFT 在单张 A100 上数小时即可完成。
- 对齐 (RLHF/RLAIF)
- 现成 Reward Model:首选,可快速迭代。
- 自训练 Reward Model:需要
- 设计多样化指令/回答集合
- 收集人类偏好标注(成对比较)
- 训练 RM → 再用 PPO/SFT 等对抗训练
- 耗时变量最大:标注难度与规模决定周期。
- 部署优化
- 常用技术:
- 8/4-bit 量化
- 知识蒸馏 → 小模型
- 编译器加速 (TensorRT / TVM)
- 验证流程:每次压缩都要重新做回归测试,确保业务指标不跌。
3 时间与难度对比(直观梯度)
预训练 ────────────────┐ ↑成本 & 复杂度
微调 (全参) ────────┘
微调 (LoRA/Prompt) ───┐
对齐 (自建 RM) ─────┘
对齐 (现成 RM) ──┐
部署优化 ────────┘
提示工程 ───────┘ ↓成本 & 复杂度
4 策略性建议
- 先易后难:
Prompt → PEFT 微调 → 现成 RLHF → (必要时) 自建 RM → 预训练
- 数据优先:小而精的指令/标注数据常常比盲目扩充参数更有效。
- 预算评估:在每一阶段前量化收益 vs. 资源投入,防止过度优化。
- 持续评估:每完成一阶段立即回到业务指标(准确率、响应速度、成本)做 A/B 测试。