指令微调 (Instruction fine-tuning)
指令微调的目的:
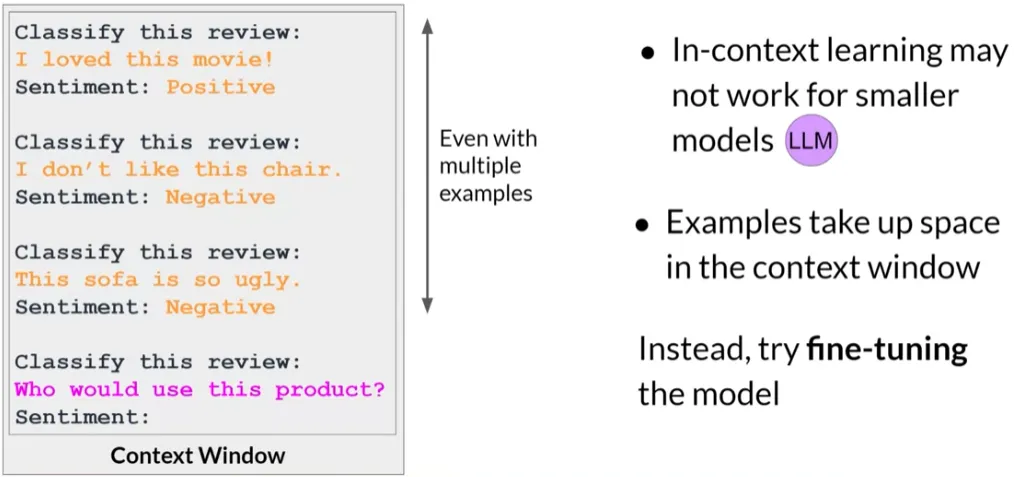
- 指令微调旨在提高现有大型语言模型(LLM)针对特定用例的性能。
- 与使用大量非结构化文本数据进行预训练不同,微调是一种有监督学习过程。
微调与预训练的区别:

预训练使用自监督学习方法,处理大量非结构化文本数据。
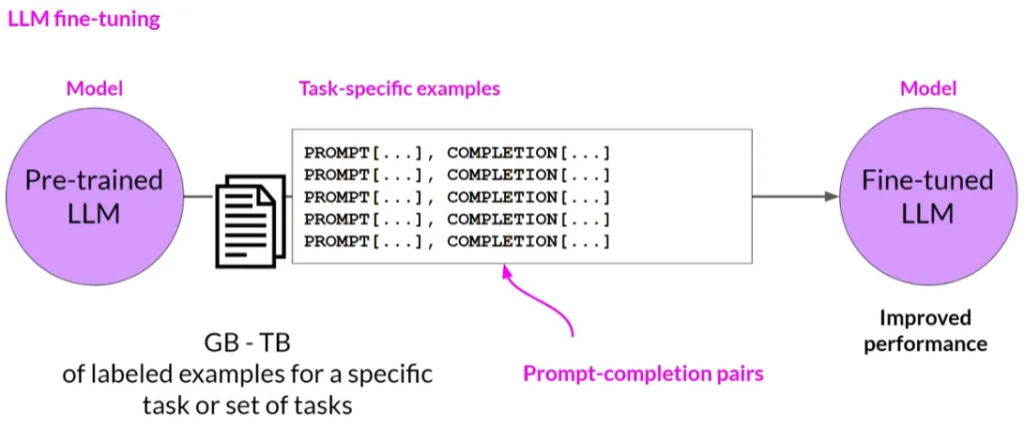
微调则使用标记好的示例数据集(例如,提示和完成对)进行训练,以提高模型在特定任务上的性能。
指令微调的过程:

指令微调训练模型使用示例,展示模型应如何响应特定指令。
训练数据集包含多个针对感兴趣任务的提示和完成示例,每个示例都包含一个指令。
指令微调的应用:

- 例如,如果你希望提高模型的总结能力,你会构建一个数据集,其中的示例以“总结以下文本”等指令开始。
- 对于改进模型的翻译技能,示例会包含诸如“翻译这句话”之类的指令。
指令微调的优势:
通过指令微调,模型学习根据给定指令生成响应。
这种微调方法更新了模型的所有权重,被称为全面微调。
微调的挑战:
- 与预训练一样,全面微调需要足够的内存和计算预算来存储和处理训练过程中更新的所有梯度、优化器和其他组件。
- 这可能需要利用内存优化和并行计算策略。
进行指令微调的步骤:
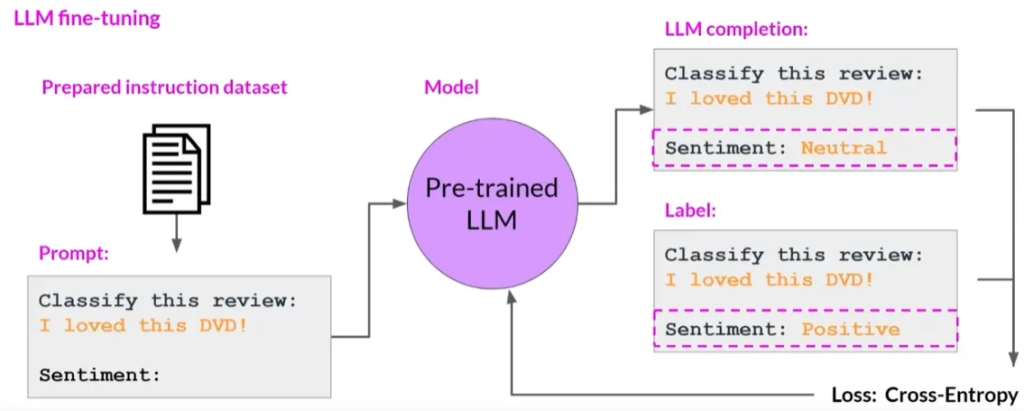
- 准备训练数据,可能需要将现有数据集格式化为指令提示数据集。

将数据集分为训练、验证和测试集。
在训练期间,选择训练集中的提示,让模型生成完成,然后将模型的完成与训练数据中指定的响应进行比
微调的结果:

- 微调的结果是一个新版本的基础模型,通常称为指令模型,在感兴趣的任务上表现更好
- 指令微调是目前微调LLM最常见的方式。
指令微调是一种有效的方法,用于提升LLM在特定任务上的性能。通过这种方法可以根据特定指令训练模型,以生成更符合需求的响应。这种方法特别适用于需要模型对特定类型的输入做出精准反应的场景。