jTrans 代码阅读笔记
https://github.com/vul337/jTrans
finetune.py
import
from unicodedata import name导入 unicodedata 模块的 name 函数。但实际上在这个程序中并未使用 name 函数。
from transformers import BertTokenizer, BertForMaskedLM, BertModel导入transformers库中的BertTokenizer、BertForMaskedLM和BertModel类。BertTokenizer用于对文本分词,BertForMaskedLM是用于MLM任务的BERT模型,BertModel是BERT基础类.
BertTokenizer、BertForMaskedLM和BertModel都是transformers库处理Bert模型的类:
- BertTokenizer: 用于将文本分割成 BERT 模型可理解的格式,包括对文本进行分词、添加特殊标记(如 [CLS] 和 [SEP])、将分词转换为 ID 等。
- BertForMaskedLM: 是一个用于MLM任务的Bert模型。MLM任务是自监督学习任务,它随机地遮挡输入文本中的一些词,并让模型预测这些被遮挡的词。
BertForMaskedLM提供了MLM任务的实现,并且包含了BERT模型的全部参数。- BertModel: 是BERT模型的基础类,它包含了BERT模型主要架构,包括自注意力层、前馈神经网络等。
BertModel可以用于各种下游任务,如文本分类、情感分析、命名实体识别等。程序虽然导入了
BertTokenizer和BertModel,但未使用BertForMaskedLM。
https://github.com/google-research/bert
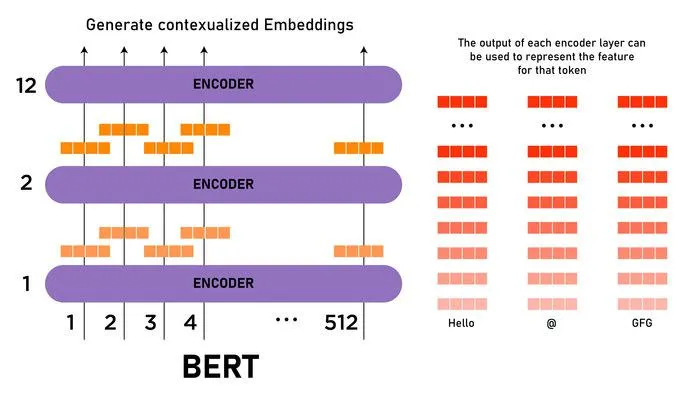
BertForMaskedLM 和 BertModel 的功能有一定程度的重叠,但它们各自有特定的应用场景。
BertModel: 这是 BERT 模型的基础实现,它包含了 BERT 的主要架构但没有任何针对特定任务(如文本分类、命名实体识别等)的附加层。你可以用它作为一个编码器来获取文本的嵌入表示,然后在其上添加额外的层以适应不同的下游任务。BertForMaskedLM: 这是专门为MLM任务设计的模型。它在BertModel的基础上添加了一个输出层,用于预测被掩码(mask)的单词。这个输出层就是与BertModel的主要区别。
BertForMaskedLM 是在 BertModel 的基础上添加了特定于 MLM 任务的输出层。如果你的任务是 MLM,使用 BertForMaskedLM 会更方便,因为它已经包含了完成这个任务所需的所有组件.
先使用MLM来预训BERT模型,然后再用这个预训练模型进行其他类型的任务,步骤如下:
步骤 1: 使用 MLM 进行预训练
使用
BertForMaskedLM来进行预训练,并可以用于学习词嵌入和其他特征。from transformers import BertForMaskedLM, BertTokenizer, DataCollatorForLanguageModeling, Trainer, TrainingArguments # 初始化 tokenizer 和 model tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForMaskedLM.from_pretrained('bert-base-uncased') # 准备数据和数据处理 data_collator = DataCollatorForLanguageModeling( tokenizer=tokenizer, mlm=True, mlm_probability=0.15 ) # 假设 train_dataset 是预处理后的训练数据 training_args = TrainingArguments( output_dir="./output", overwrite_output_dir=True, num_train_epochs=1, per_device_train_batch_size=32, save_steps=10_000, save_total_limit=2, ) trainer = Trainer( model=model, args=training_args, data_collator=data_collator, train_dataset=train_dataset, ) # 开始预训练 trainer.train()步骤 2: 保存预训练的模型
预训练完成后,你应该保存模型,以便稍后用于其他任务。
model.save_pretrained("./output/pretrained_model")步骤 3: 加载预训练的模型进行下游任务
当你需要使用预训练的模型进行其他任务时,你可以加载这个模型,然后在其上添加额外的层以适应新任务。
from transformers import BertForSequenceClassification # 加载预训练的模型 model = BertForSequenceClassification.from_pretrained("./output/pretrained_model", num_labels=num_labels) # num_labels 是你的分类任务的类别数
import torch.multiprocessing导入 torch.multiprocessing 模块,用于多进程训练。
from torch.utils.data import DataLoader导入 DataLoader 类,用于加载数据。
import os导入 os 模块,用于处理文件和目录。
import torch导入 torch 模块,PyTorch 的基础模块。
import torch.nn as nn导入 torch.nn 模块,并将其命名为 nn,用于定义和使用神经网络。
import numpy as np导入 numpy 模块,并将其命名为 np,用于数值计算。
from tqdm import tqdm导入 tqdm 模块,用于显示进度条。
from data import load_paired_data, FunctionDataset_CL, FunctionDataset_CL_Load从 data 模块导入 load_paired_data、FunctionDataset_CL 和 FunctionDataset_CL_Load 类。这些类用于加载和处理数据。
from transformers import AdamW从 transformers 模块导入 AdamW 类,用于优化。
import torch.nn.functional as F导入 torch.nn.functional 模块,并将其命名为 F,用于使用神经网络的功能函数。
import argparse导入 argparse 模块,用于解析命令行参数。
import wandb导入 wandb 模块,用于记录实验数据。
import logging导入 logging 模块,用于记录日志。
import sys导入 sys 模块,用于访问 Python 运行时的一些变量和函数。
import time导入 time 模块,用于处理时间。
import data导入 data 模块。
import pickle导入 pickle 模块,用于序列化和反序列化对象。
WANDB = True定义一个全局变量WANDB,用于控制是否使用wandb记录实验数据。接下来的代码定义了两个函数 get_logger 和 train_dp,以及一个 BERT 模型的变种 BinBertModel。
wandb(weights and biases)是一个用于机器学习项目实验追踪工具。可以监控模型训练过程中的各种指标,例如损失函数值、准确率等,提供了可视化界面,用于分析模型性能.
初始化 Wandb
代码中用
wandb.init()初始化了 Wandb,并设置了项目名称和运行名称。if WANDB: wandb.init(project=f'jTrans-finetune', name="jTrans_Freeze_10_Train_Test")更新配置参数
通过
wandb.config.update(args),代码将命令行参数args更新到Wandb的配置中:wandb.config.update(args)日志记录
在训练循环中,使用
wandb.log()记录重要指标,如三元组损失(triplet loss)、学习率和全局步数。if WANDB: wandb.log({ 'triplet loss' : loss, 'lr' : tmp_lr, 'global_step' : global_steps, })在模型验证部分,代码也用
wandb.log()记录了 MRR 值。if WANDB: wandb.log({ 'mrr': mrr })
get_logger
def get_logger(name):
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', filename=name)
logger = logging.getLogger(__name__)
s_handle = logging.StreamHandler(sys.stdout)
s_handle.setLevel(logging.INFO)
s_handle.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(filename)s[:%(lineno)d] - %(message)s"))
logger.addHandler(s_handle)
return logger用于初始化一个日志记录器。首先,使用 logging.basicConfig 设置日志的基本配置,包括日志级别、格式和输出文件名。然后,创建一个日志记录器,并添加一个流处理器,将日志输出.
train_dp
def train_dp(model, args, train_set, valid_set, logger):这个函数是模型训练的主体部分。函数接受五个参数:模型、命令行参数、训练集、验证集和日志记录器。
class Triplet_COS_Loss(nn.Module):
def __init__(self, margin):
super(Triplet_COS_Loss, self).__init__()
self.margin = margin
def forward(self, repr, good_code_repr, bad_code_repr):
good_sim = F.cosine_similarity(repr, good_code_repr)
bad_sim = F.cosine_similarity(repr, bad_code_repr)
loss = (self.margin - (good_sim - bad_sim)).clamp(min=1e-6).mean()
return loss这个类定义了一个三元组损失函数,用于比较代码片段的相似性。损失函数计算了一个锚点代码片段与一个正例代码片段的余弦相似度,以及锚点代码片段与一个负例代码片段的余弦相似度。损失值是正例相似度与负例相似度之差减去一个边界值的最小值。
接下来的代码设置了一些训练参数,初始化模型和数据加载器。
if WANDB:
wandb.init(project=f'jTrans-finetune', name="jTrans_Freeze_10_Train_Test")
wandb.config.update(args)如果 WANDB 为 True,则初始化 wandb 并更新配置参数。
接下来的代码是模型训练的主循环。
for epoch in range(args.epoch):
model.train()
triplet_loss = Triplet_COS_Loss(margin=0.2)
train_iterator = tqdm(train_dataloader)
loss_list = []
for i, (seq1, seq2, seq3, mask1, mask2, mask3) in enumerate(train_iterator):
...训练过程
模型训练的核心部分主要用于训练一个基于三元组损失(Triplet Loss)的模型:
for i, (seq1, seq2, seq3, mask1, mask2, mask3) in enumerate(train_iterator)::这一行开始了一个循环,它遍历训练数据集。 每次迭代, 它从数据加载器中获取一批数据, 其中包含三组序列(seq1,seq2,seq3)和对应的注意力掩码(mask1,mask2,mask3)。 打印某个seq的输出为:
tensor([
[2900, 513, 520, …, 2899, 2899, 2899],
[2900, 513, 525, …, 2899, 2899, 2899],
[2900, 514, 515, …, 2899, 2899, 2899],
…,
[2900, 513, 517, …, 2899, 2899, 2899],
[2900, 513, 525, …, 2899, 2899, 2899],
[2900, 513, 525, …, 2899, 2899, 2899]])
每一行代表 batch 中的一个样本。这个 tensor 是一个形状为 [N, L] 的二维张量,其中 N 是 batch 大小,即 batch 中包含的样本数量,而 L 是每个样本的序列长度。通常用于批量处理,以便一次通过网络传递多个样本,从而提高计算效率。 每行是一个独立的输入序列, 由一系列 token IDs 组成。 IDs 是通过分词器(例如 BERT 的分词器)从原始文本转换而来的。 通常,在这样的 tensor 中,不同的行(即不同的样本)可能已经被填充(padding)到相同的长度L以便能够组成一个矩形的张量。这是常见的做法,用于处理不同长度的输入序列。t1 = time.time(): 记录当前时间,用于计算这一批数据的处理时间。input_ids1, attention_mask1 = seq1.cuda(), mask1.cuda(): 将seq1和mask1移动到GPU;input_ids2, attention_mask2 = seq2.cuda(), mask2.cuda(): 将seq2和mask2移动到GPU;input_ids3, attention_mask3 = seq3.cuda(), mask3.cuda(): 将seq3和mask3移动到GPU;optimizer.zero_grad(): 在进行新的优化迭代之前,将模型的梯度设置为零;anchor, pos, neg = 0, 0, 0: 初始化三个变量,用于存储三组数据模型输出;output1 = model(input_ids=input_ids1, attention_mask=attention_mask1): seq1的输出;anchor = output1.pooler_output: 获取第一组数据(锚点)的池化输出;output2 = model(input_ids=input_ids2, attention_mask=attention_mask2): seq2的输出;pos = output2.pooler_output: 获取第二组数据(正样本)的池化输出;output3 = model(input_ids=input_ids3, attention_mask=attention_mask3): seq3的输出;neg = output3.pooler_output: 获取第三组数据(负样本)的池化输出; 在 BERT 和其他 Transformer 模型中,池化输出通常是指从模型最后一个隐藏层获取的固定大小的向量,这个向量是整个输入序列的某种表示。池化输出与模型的直接输出的区别:- 模型的直接输出:
- 在 BERT 和其他 Transformer 模型中,直接输出通常是一个三维张量,形状为 [N, L, D],其中$N$是 batch 大小,L是序列长度,D 是隐藏层的维度。这个输出为输入序列中的每个 token 都提供了一个 D -维的向量表示。
- 池化输出通常是一个二维张量,形状为 [N, D]。这个输出只为整个输入序列提供了一个D-维的向量表示,通常是通过某种池化(如平均池化,最大池化或特定token
[CLS]的输出)从模型的直接输出获取.
[CLS]token 的输出作为整个序列的池化输出。这是因为 BERT 被训练来使[CLS]token 的输出能够作为整个输入序列的有效表示。output1 = model(input_ids=input_ids1, attention_mask=attention_mask1)anchor = output1.pooler_outputoutput1.pooler_output很可能就是[CLS]token 经过池化层后的输出,用作整个序列的表示。这个 “池化输出” 通常用于下游任务,如文本分类、文本匹配等。- 模型的直接输出:
optimizer.zero_grad(): 再次将模型的梯度设置为零(这似乎是多余的);loss = triplet_loss(anchor, pos, neg): 使用三元组损失函数计算损失;loss.backward(): 计算损失相对于模型参数的梯度;loss_list.append(loss): 将这一批数据的损失添加到损失列表中;optimizer.step(): 更新模型的权重;if (i+1) % args.log_every == 0:: 检查是否达到了记录日志的条件;global_steps += 1: 更新全局步数;tmp_lr = optimizer.param_groups[0]["lr"]: 获取当前的学习率;train_iterator.set_description(...): 更新训练迭代器的描述,通常会显示在进度条上。if WANDB:: 检查是否使用了 Weights and Biases;wandb.log({...}): 记录三元组损失、学习率和全局步数到 Weights and Biases;
这个循环负责模型的整个训练过程。它读取数据、通过模型进行前向传播、计算损失、进行反向传播和优化,还可选地记录训练过程的各种指标。
每个 epoch 都会遍历整个训练集,计算损失值并进行反向传播更新模型参数。
if (epoch + 1) % args.eval_every == 0:
logger.info(f"Doing Evaluation ...")
mrr = finetune_eval(model, valid_dataloader)
logger.info(f"[*] epoch: [{epoch}/{args.epoch+1}], mrr={mrr}")
if WANDB:
wandb.log({'mrr': mrr})在每个 eval_every 个 epoch 后,会在验证集上评估模型的性能,并记录 MRR 值。
if (epoch + 1) % args.save_every == 0:
logger.info(f"Saving Model ...")
model.module.save_pretrained(os.path.join(args.output_path, f"finetune_epoch_{epoch + 1}"))
logger.info(f"Done")在每个 save_every 个 epoch 后,会保存模型的参数。
finetune_val
接下来的代码定义了一个评估函数 finetune_eval,用于在验证集上评估模型的性能。
def finetune_eval(net, data_loader):
...这个函数计算了模型在验证集上的 MRR 值。
接下来的代码定义了一个 BERT 模型的变种 BinBertModel。
class BinBertModel(BertModel):
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings.position_embeddings = self.embeddings.word_embeddings这个类继承自 BertModel,并重写了其 __init__ 方法。在这个变种中,位置嵌入被设置为和词嵌入相同。
在这个实现中
position_embeddings被设置为与word_embeddings相同,原来独立学习的position_embeddings不再起独立的作用。这意味着这两组嵌入现在共享相同的权重。然而位置信息并没有完全丢失。Transformer架构(包括 BERT)自注意力机制有能力捕获序列中的顺序和位置信息,尽管通常不如专门设计的位置嵌入
position_embeddings有效.所以,在这个特定的模型实现中,由于
position_embeddings被word_embeddings覆盖,其对模型的影响会减弱,但由于 Transformer 的自注意力机制,位置信息并不会完全丢失.为什么作者要这么设置?
https://github.com/vul337/jTrans/issues/3
https://github.com/vul337/jTrans/issues/11
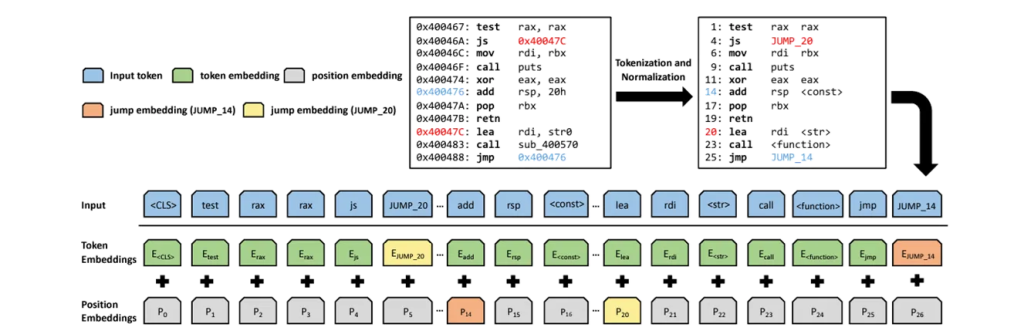
首先看到在vocab.txt文件中的前512行均是JUMP_ADDR_XX的形式的tokens。
首先,
self.embeddings.position_embeddings和self.embeddings.word_embeddings都是嵌入矩阵,而不是某个特定 token 序列的嵌入结果。
self.embeddings.word_embeddings通常是一个形状为[vocab_size, embedding_dim]的矩阵,其中vocab_size是词汇表的大小,embedding_dim是嵌入向量的维度。self.embeddings.position_embeddings是形状为[max_seq_length, embedding_dim]的矩阵,用于保存序列中每个位置的嵌入。在
BinBertModel类中,作者将position_embeddings设置为与word_embeddings相同。这意味着模型在查找位置嵌入时实际上会使用word_embeddings矩阵中相应行。比如指令JUMP_ADDR_500 的 input_id 是500,那么 500 由于在max_seq_length的范围内,因此其 word_embedding 的结果会与 position_embedding的结果相同,从而实现了参数共享。另外,在BERT(Bidirectional Encoder Representations from Transformers)模型,序列的最大长度通常是一个预先定义的参数。在很多实现中,这个最大长度确实被设置为512个tokens。并不是说输入序列必须是512个tokens 长,而是说它不能超过这个长度。较短序列会被填充。
position_embeddings矩阵的形状是[max_seq_length, embedding_dim],其中max_seq_length是模型可以接受最大序列长度(这里是512),而embedding_dim是嵌入向量的维度(在这里是768)。
接下来的代码是命令行参数的解析和模型训练的主体部分。
if __name__ == "__main__":
...这个部分首先设置了多进程的共享策略,然后解析了命令行参数,并初始化了日志记录器、模型和分词器。接下来的代码加载了训练数据和验证数据,并调用 train_dp 函数进行模型训练.
train_dp(model, args, ft_train_dataset, ft_valid_dataset, logger)最后,输出了一条日志信息,表示训练已完成。
logger.info("Finished Training")这就是整个程序的解释。如果你有任何疑问,或者需要更详细的解释,请随时告诉我。
fasteval.py
import
import pickle
import sys
from datautils.playdata import DatasetBase as DatasetBase
from torch.utils.data import DataLoader
import torch
import torch.nn.functional as F
import numpy as np
from tqdm import tqdm
import argparsepickle: 用于序列化和反序列化Python对象。sys: 系统相关的操作。DatasetBase: 从datautils.playdata导入的自定义数据集基类。DataLoader: PyTorch的数据加载器。torch: PyTorch库,用于深度学习。torch.nn.functional: 包含一系列PyTorch的函数。numpy as np: 数学运算库。tqdm: 进度条库。argparse: 用于解析命令行参数。
eval_O
def eval_O(ebds,TYPE1,TYPE2):定义一个名为eval_O的函数,接受嵌入字典ebds和两种类型的优化标签TYPE1、TYPE2。
funcarr1=[]
funcarr2=[]初始化两个空数组,用于存储两种类型的嵌入。
for i in range(len(ebds)):
if ebds[i].get(TYPE1) is not None and type(ebds[i][TYPE1]) is not int:
if ebds[i].get(TYPE2) is not None and type(ebds[i][TYPE2]) is not int:遍历嵌入字典,检查每个字典元素是否包含有效的TYPE1和TYPE2嵌入。
ebd1,ebd2=ebds[i][TYPE1],ebds[i][TYPE2]
funcarr1.append(ebd1 / ebd1.norm())
funcarr2.append(ebd2 / ebd2.norm())如果找到有效的嵌入,进行L2归一化并存储。
创建数据集和数据加载器
ft_valid_dataset=FunctionDataset_Fast(funcarr1,funcarr2)
dataloader = DataLoader(ft_valid_dataset, batch_size=POOLSIZE, num_workers=24, shuffle=True)使用筛选和归一化后的嵌入创建一个数据集,并通过PyTorch的DataLoader进行批量加载。
初始化性能指标数组
SIMS=[]
Recall_AT_1=[]初始化用于存储Mean Reciprocal Rank(MRR)和Recall@1的数组。
主循环:计算相似度和性能指标
for idx, (anchor,pos) in enumerate(tqdm(dataloader)):遍历每一个批次的数据。
anchor = anchor.cuda()
pos =pos.cuda()将数据移动到GPU上。
if anchor.shape[0]==POOLSIZE:检查批次大小是否等于预定义的POOLSIZE。
for i in range(len(anchor)): # check every vector of (vA,vB)
vA=anchor[i:i+1] #pos[i]
sim = np.array(torch.mm(vA, pos.T).cpu().squeeze())对于每一个anchor,计算与pos的所有元素之间的相似度。
y=np.argsort(-sim)对相似度进行降序排序。
posi=0
for j in range(len(pos)):
if y[j]==i:
posi=j+1
break找到原始anchor在排序后的位置。
if posi==1:
Recall_AT_1.append(1)
else:
Recall_AT_1.append(0)
SIMS.append(1.0/posi)更新Recall@1和MRR。
打印性能指标
print(TYPE1,TYPE2,'MRR{}: '.format(POOLSIZE),np.array(SIMS).mean())
print(TYPE1,TYPE2,'Recall@1: ', np.array(Recall_AT_1).mean())计算并打印MRR和Recall@1。
FunctionDataset_Fast
class FunctionDataset_Fast(torch.utils.data.Dataset):
def __init__(self,arr1,arr2):
self.arr1=arr1
self.arr2=arr2
assert(len(arr1)==len(arr2))
def __getitem__(self, idx):
return self.arr1[idx].squeeze(0),self.arr2[idx].squeeze(0)
def __len__(self):
return len(self.arr1)这个类继承自torch.utils.data.Dataset,用于自定义数据加载。
main
if __name__ == '__main__':定义主函数。
解析命令行参数
parser = argparse.ArgumentParser(description="jTrans-FastEval")
parser.add_argument("--experiment_path", type=str, default='./experiments/BinaryCorp-3M/jTrans.pkl', help="experiment to be evaluated")
parser.add_argument("--poolsize", type=int, default=32, help="size of the function pool")
args = parser.parse_args()使用argparse解析命令行参数。
加载嵌入
POOLSIZE=args.poolsize
ff=open(args.experiment_path,'rb')
ebds=pickle.load(ff)
ff.close()从指定路径加载嵌入,并设置POOLSIZE。
执行评估
print(f'evaluating...poolsize={POOLSIZE}')
eval_O(ebds,'O0','O3')
eval_O(ebds,'O0','Os')
eval_O(ebds,'O1','Os')
eval_O(ebds,'O1','O3')
eval_O(ebds,'O2','Os')
eval_O(ebds,'O2','O3')调用eval_O函数进行评估。
pkl
import pickle
from pprint import pformat
# Load the pickle file
file_path = './small_train/9base-grep/saved_index.pkl' # Replace this with the actual path to your .pkl file
with open(file_path, 'rb') as f:
data = pickle.load(f)
# Inspect the type and content of the loaded data
print("Type of data:", type(data))
with open("output.txt", "w") as f:
f.write(pformat(data))打印BinaryCorp的./small_train/9base-grep/saved_index.pk内容: