基于LLM的生成式AI应用架构 (LLM application architectures)
黎 浩然/ 1 12 月, 2023/ 大语言模型/LARGELANGUAGEMODEL/LLM, 机器学习/MACHINELEARNING, 研究生/POSTGRADUATE, 计算机/COMPUTER/ 0 comments
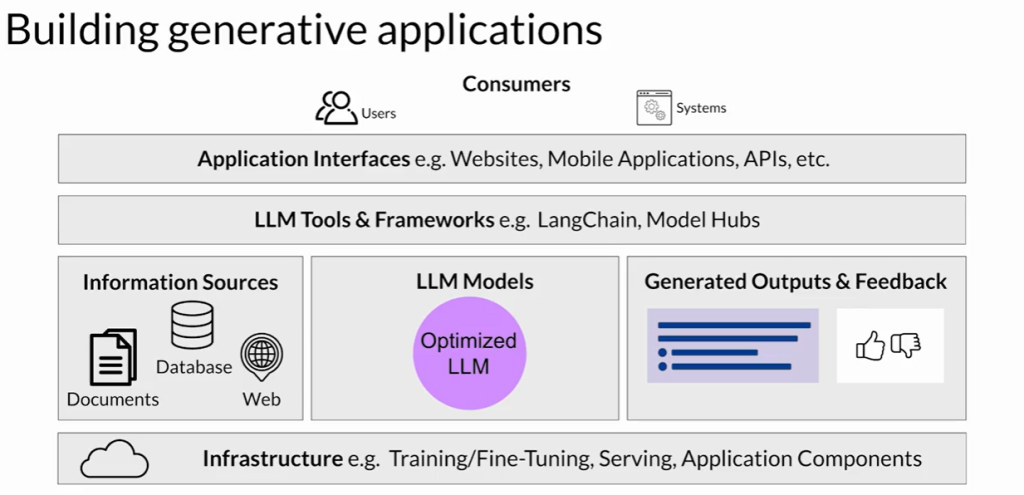
一、构建LLM应用的关键组成部分(LLM应用的技术栈)
- 基础设施层(Infrastructure Layer)
- 提供计算、存储和网络资源。
- 可选择本地部署或使用按需计费的云服务。
- 支持大模型推理及应用组件的部署。
- 模型层(Model Layer)
- 包括基础模型(Foundation Models)和任务定制模型(Fine-tuned Models)。
- 部署时需考虑是否需要实时或近实时的推理响应能力。
- 外部信息检索(External Retrieval)
- 若模型上下文窗口不足,可结合“检索增强生成”(RAG)机制。
- 可从外部数据库、文档或API获取信息来辅助推理。
- 输出与反馈(Outputs & Feedback)
- 返回生成结果给用户或调用方(如其他系统或API)。
- 可选择性地存储用户会话中的输出,用于上下文增强或后续微调。
- 用户反馈可用于模型的再训练、调优和评估。
- 工具与框架(LLM工具与开发框架)
- 示例工具:LangChain(支持ReAct、Chain of Thought、RAG等)。
- 可借助模型中心(Model Hub)进行模型管理与共享。
- 用户界面与安全层(UI & Security)
- 提供交互界面,如网页端或REST API。
- 配置必要的身份验证与访问控制机制,保障数据与用户安全。
二、模型优化技术
- 推理优化(Inference Optimization)
- 通过模型蒸馏(Distillation)、量化(Quantization)、**剪枝(Pruning)**来减小模型体积,降低计算资源消耗。
- 结构化提示与外部连接(Structured Prompting & External Connections)
- 使用明确的提示模板(Prompt Templates)提高推理表现。
- 利用外部工具(如Python解释器、数据库)增强模型能力。
三、对齐与人类偏好(Human Alignment)
- RLHF(Reinforcement Learning with Human Feedback)
- 即“人类反馈强化学习”,用于将模型调优为更有用、无害、诚实。
- 越来越多的人类对齐数据集(Alignment Datasets)和奖励模型(Reward Models)可供使用,便于快速启动对齐训练。
- RLHF可有效减少有害输出、提升安全性和可信度。
四、未来发展趋势与研究方向(Active Research Directions)
- 模型对齐技术将持续进化,以更好适应真实世界中的安全和伦理需求。
- 模型部署效率将进一步优化,以便在低资源环境中高效运行。
- LangChain等开发框架正在快速演进,帮助开发者更快地构建和部署智能应用。
- LLM将成为智能应用的推理引擎,通过与外部工具联动,实现“可调用、可连接、可思考”的AI系统。
✨ 总结
- 构建一款LLM驱动的AI应用并不只是模型本身,还涉及部署、交互、安全、反馈、优化等多个环节。
- RLHF、推理优化和结构化提示是当前应用性能提升的三大关键策略。
- 工具链(如LangChain)和开发生态的丰富,为开发者带来了前所未有的创造力和机会。
- 未来将是开发者和AI协同演进的时代,现在正是加入这一浪潮的最佳时机。