大型语言模型 Benchmarks
在讨论大型语言模型(LLM)评估时,我们关注的不仅是简单评价指标(ROUGE和BLEU),而是需要更全面的基准测试。这些基准测试利用预先存在的数据集来全面衡量和比较LLM性能.以下是一些主要的基准测试及其特点:
选择合适的评估数据集:
- 选择正确的评估数据集至关重要,以准确评估LLM的性能并理解其真实能力。
- 应选择那些能够隔离特定模型技能(如推理或常识知识)的数据集,以及那些关注潜在风险(如虚假信息或侵权)的数据集。
GLUE(General Language Understanding Evaluation):GLUE Benchmark
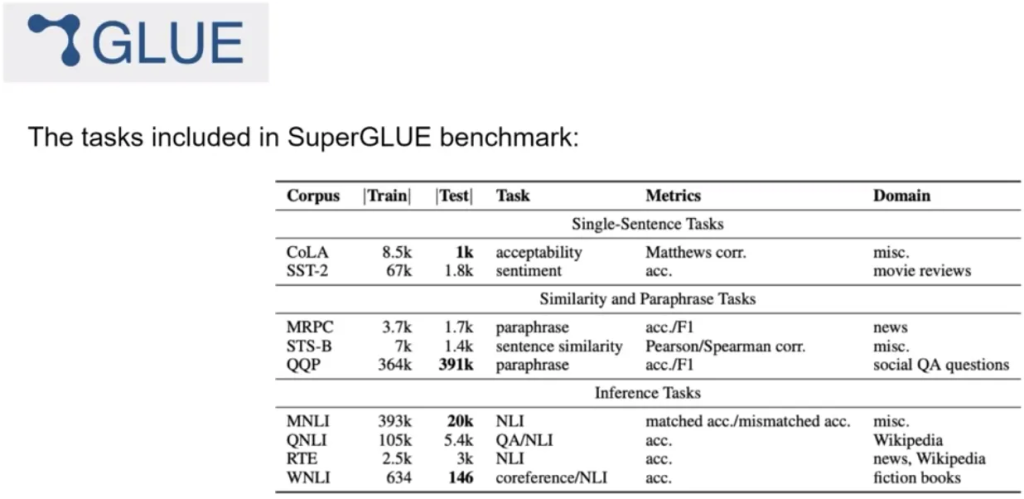
- 介绍于2018年,包括自然语言处理任务,如情感分析和问答。
- 旨在鼓励开发能够在多个任务中泛化的模型。
- 可用于衡量和比较模型性能。
SuperGLUE: SuperGLUE Benchmark
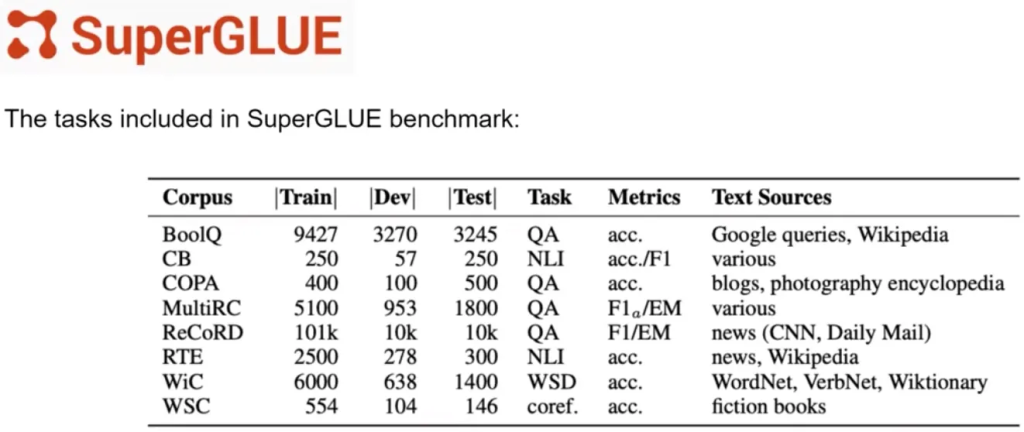
- 作为GLUE的继任者于2019年推出,旨在解决GLUE的局限性。
- 包含一系列任务,有些不包含在GLUE中,有些则是更具挑战性的相同任务。
- 包括多句推理和阅读理解等任务。
- 与GLUE一样,有排行榜用于比较和对比评估模型。
Massive Multitask Language Understanding (MMLU): Papers with Code – MMLU Dataset
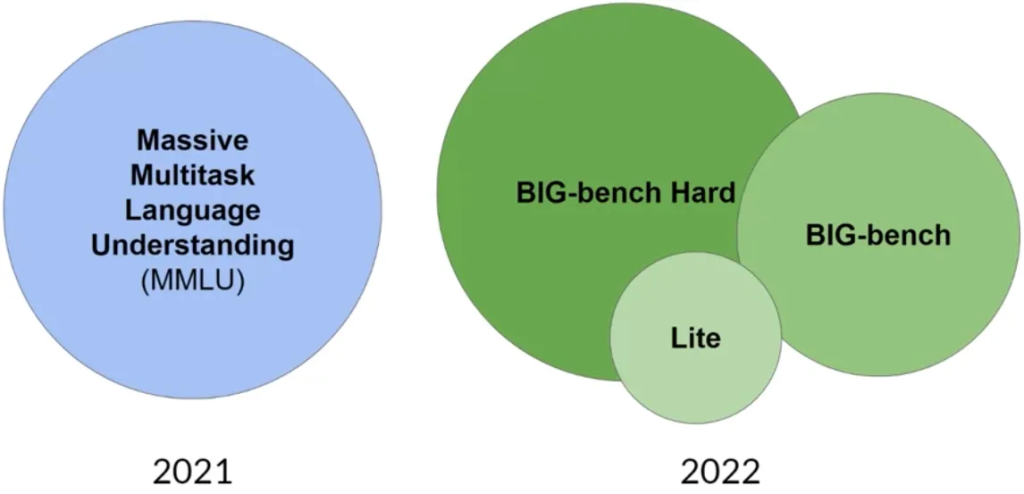
- 专为现代LLM设计,测试模型在基础数学、美国历史、计算机科学、法律等领域的知识和解决问题能力。
BIG-bench: https://github.com/google/BIG-bench
- 包含204个任务,涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等。
- 提供三种不同规模的测试,考虑到运行这些大型基准测试的成本。
Holistic Evaluation of Language Models (HELM):
Holistic Evaluation of Language Models (HELM)
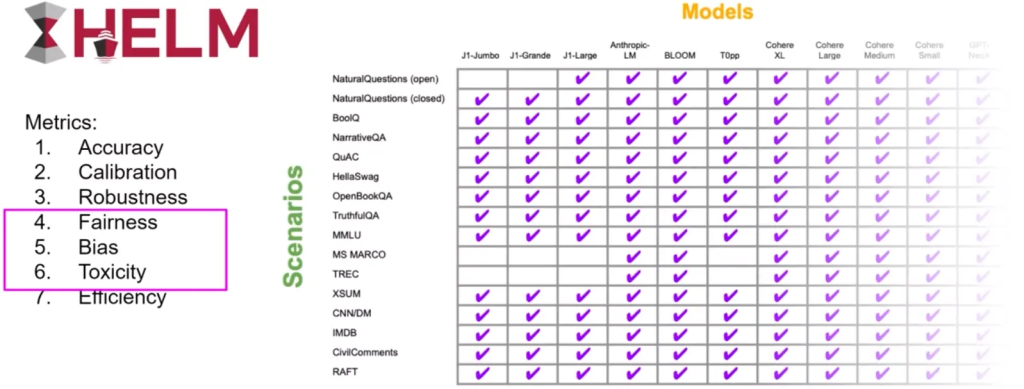
- 旨在提高模型的透明度,并为特定任务性能良好的模型提供指导。
- 采用多指标方法,跨越16个核心场景测量七个指标,确保模型和指标之间的权衡清晰可见。
- 包括公平性、偏见和有害性等指标,这些在LLM越来越能生成类似人类的语言(从而可能表现出潜在有害行为)时变得越发重要。
这些基准测试为LLM的综合评估提供了丰富的资源,可以帮助研究者和开发者更准确地理解和比较不同模型在各种任务上的表现。随着LLM技术的发展,这些基准测试也在不断演变和更新,以适应新的挑战和需求。