LLM的推理能力与链式思考 (Helping LLMs reason and plan with chain-of-thought)
一、LLM在推理任务中的局限性
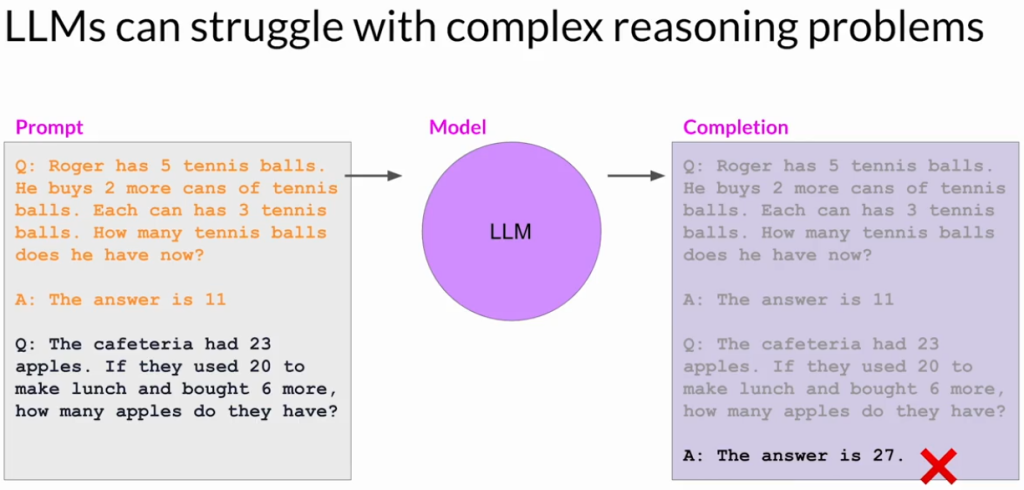
- 大型语言模型(LLM)通常在执行多步推理或数学问题时表现不佳,即使在其他任务上有良好表现。
- 举例说明:
- 模型在解决多步骤的简单数学问题(例如计算餐厅剩余苹果数)时犯了错误。
- 模型错误地得出27个苹果,实际答案应为9个。
二、提升LLM推理能力的方法:Chain-of-Thought Prompting
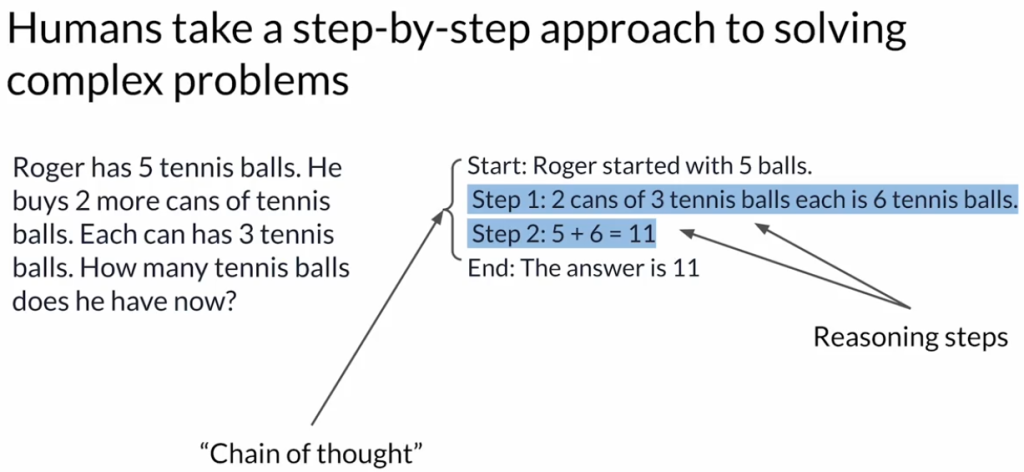
1. 什么是Chain-of-Thought Prompting?
- 引导模型模仿人类的推理方式,将复杂问题分解为多个清晰的步骤逐步解决。
- 通过提供中间推理步骤作为示范,让模型学习如何一步步地推导出正确答案。
2. 示例讲解
- 以“Roger买网球”的示例为一-shot prompt:
- 初始状态:Roger原有5个网球。
- 新购入:2罐网球,每罐3个,总计6个。
- 计算:初始5个 + 新增6个 = 11个。
- 最终答案:Roger共有11个网球。
- 当模型接受这种链式推理的prompt后,能更清晰地理解并准确解决类似问题。
三、Chain-of-Thought Prompting的应用效果
1. 苹果问题的重做(示例)

- 使用链式思考重新设计prompt后,模型成功地进行以下推理步骤:
- 初始苹果数量。
- 减去用于午餐的苹果数量。
- 再加入后来购买的苹果数量。
- 最终模型给出正确答案(剩余9个苹果)。
2. 物理学问题示例

- 问题:判断一个金戒指在游泳池中是否会下沉。
- 推理步骤示例:
- 明确物体的密度概念。
- 指出金的密度大于水,因此得出戒指会下沉的结论。
四、Chain-of-Thought Prompting的优势与局限
- 优势:显著提高模型在多步骤推理任务中的表现;帮助模型清晰地展示其推理过程。
- 局限:虽然能改善推理过程,但LLM本身的数学能力依旧有限,不适合处理需要高度精确计算的任务(例如电子商务中的总额计算、税费计算或折扣计算)。
五、后续技术展望
- 下一步将探索如何通过让LLM与更擅长数学运算的外部程序协作,进一步解决模型在精确计算方面的不足。
总结:Chain-of-Thought Prompting通过明确、逐步的中间步骤提示,帮助LLM模仿人类思维,更好地完成推理和计算任务,提升了其处理复杂问题的准确性和透明度。但当涉及精确计算时,仍需借助外部程序的辅助。