大语言模型部署与优化 (Model optimizations for deployment)
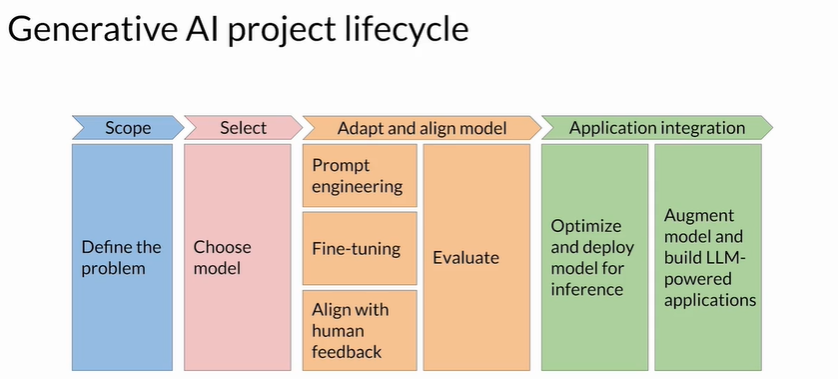
1 部署前的关键思考
- 推理性能
- 速度:目标端到端延迟多少毫秒?
- 计算预算:GPU/CPU 数量与规格,是否允许多实例并行?
- 权衡:能接受多少精度损失来换取更快的推理或更小模型?
- 外部依赖
- 数据:模型是否需检索向量库、SQL 或其他实时数据?
- 应用集成:如何安全、低延迟地调用这些资源(RAG、API、数据库连接等)?
- 消费方式
- 接口设计:REST、gRPC 还是 WebSocket?
- 应用形态:云端服务、移动端、边缘设备?不同形态决定不同优化侧重。
2 模型优化三大技术
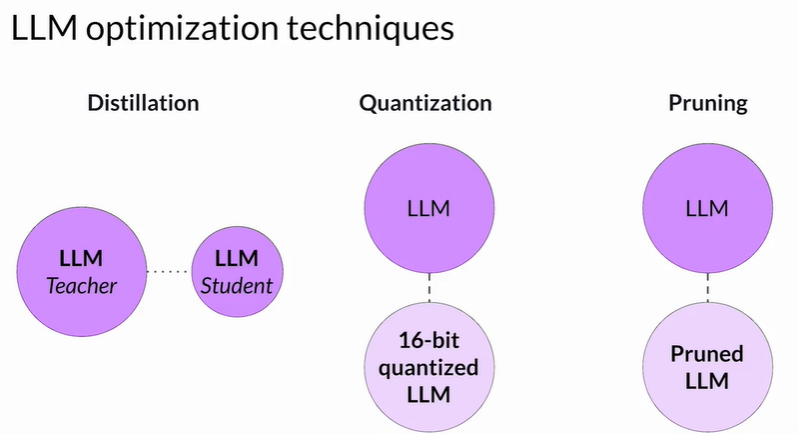
目标:在保持可接受精度的前提下,降低存储占用与推理延迟。
| 技术 | 思想 | 实施阶段 | 优点 | 注意事项 |
|---|---|---|---|---|
| 蒸馏 (Distillation) | 用大教师模型指导小学生模型学习,学生用于部署 | 重新训练(需训练数据) | 学生模型体积小、推理快 | 对解码型生成模型效果有限;需额外训练成本 |
| 量化 (Quantization) | 将参数从 FP32 压缩为 FP16 / INT8 | PTQ:训练后 QAT:训练中 | 显著减小模型 & VRAM;可配合硬件加速 | INT8 需校准;同时量化激活层会略降精度 |
| 剪枝 (Pruning) | 删除权重≈0 的冗余连接 | 训练中 / 训练后 | 理论上减小参数量 | 若只剪掉少量权重,压缩收益有限;部分方法需重新训练 |
2.1 知识蒸馏流程
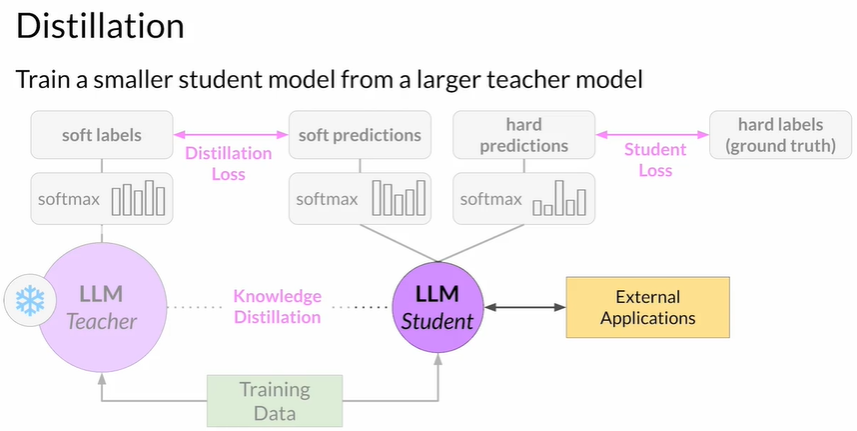
- 准备
- 教师:已微调的完整 LLM(冻结权重)
- 学生:较小的 LLM 初始化
- 双路推理
- 对同一训练样本,教师输出 soft labels(经高温度 Softmax,分布更平滑)
- 学生正常输出 hard predictions
- 损失函数
- 蒸馏损失:学生输出 vs 教师 soft labels
- 学生损失:学生输出 vs 真实标签
- 总损失 = 两者加权
- 反向传播:仅更新学生权重
- 部署:只使用学生模型,节省推理成本
适用:BERT 等编码器模型冗余度高;生成式解码模型增益较小。
2.2 量化要点
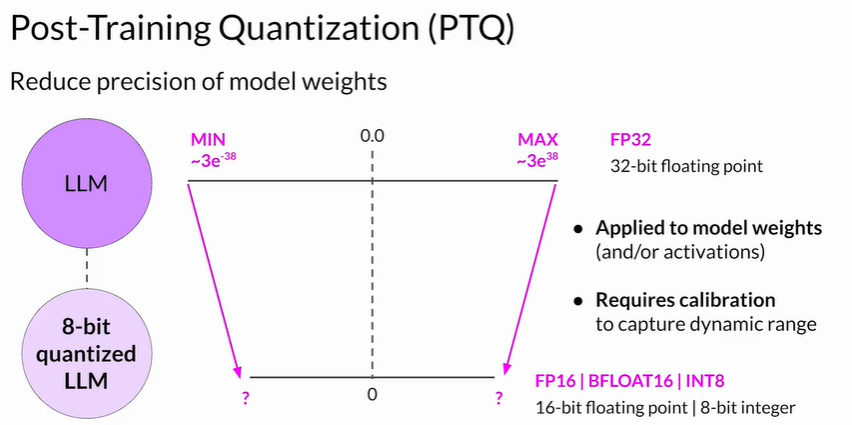
- PTQ(Post-Training Quantization)
- 仅需少量校准数据;不改动训练流程
- 可选择只权重或权重+激活量化
- QAT(Quantization-Aware Training)
- 在训练时插入伪量化节点,效果优于 PTQ
- 精度取舍
- FP16:几乎无精度损失,推理翻倍提速
- INT8:显存再减半,可能带来 1%–3% 精度下降
2.3 剪枝分类

| 类别 | 描述 | 是否需再训练 |
|---|---|---|
| 全量剪枝 | 基于阈值直接去零权重 | 否,效果有限 |
| 迭代剪枝 | 剪→微调交替多轮 | 是,保持精度 |
| 结构化剪枝 | 按通道/头/层删除 | 需改模型架构,最易获得实际加速 |
3 选择与组合策略
- 边缘部署:优先 PTQ→INT8,必要时配合小学生蒸馏。
- 云端高 QPS:蒸馏 + FP16 量化,可维持较高精度同时降低成本。
- 极限压缩:蒸馏(大幅缩短参数)→ QAT INT8 → 结构化剪枝。逐层评估精度。
4 实战落地流程(建议)
- 性能基线:记录未优化模型的时延、吞吐、显存占用
- 快速试点
- 先做 Post-Training FP16 量化,评估影响
- 如需进一步下降显存/时延,再尝试 INT8 + 校准
- 蒸馏/剪枝实验
- 蒸馏:准备数据,训练学生模型,看精度与体积变化
- 剪枝:若仍超预算,选择结构化剪枝并重新微调
- 监控与回滚
- 建立 A/B 测试,观察线上指标(延迟/出错率/用户满意度)
- 一旦精度跌破阈值,自动回滚上一版本
- 自动化 CI/CD
- 把量化、蒸馏、剪枝脚本化,持续集成
- 推理服务容器化,多版本灰度发布
5 关键 takeaway
- 优化先量化,后必要再蒸馏/剪枝,逐级迭代、监控收益。
- 始终以业务指标为准:精度最低可接受线先行;成本、延迟相对于它调整。
- 软硬件协同:硬件支持 INT8/FP16(TensorRT、ONNX Runtime、xPU 指令集)能大幅放大利益。