大语言模型生成式配置 (LLM Generative configuration)
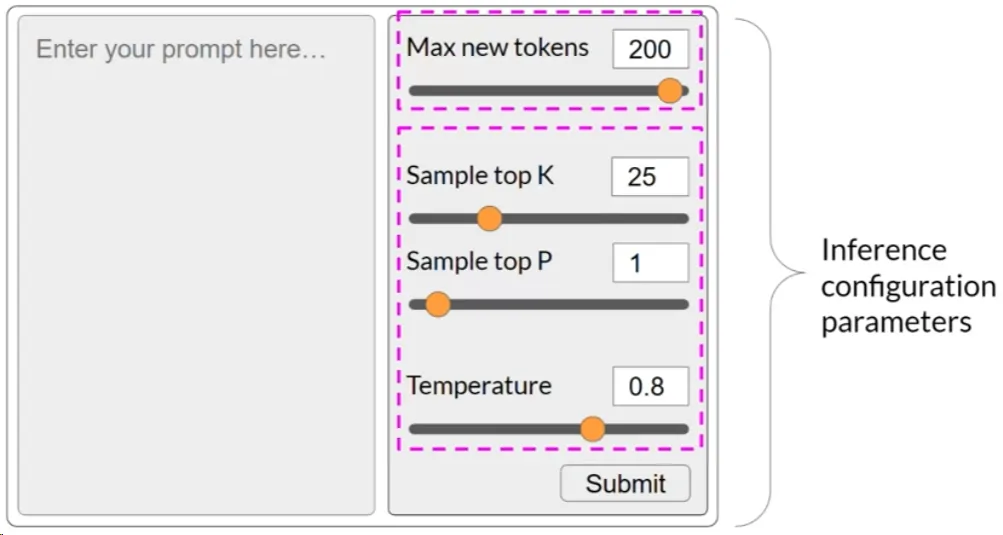
Inference Configuration Parameters
最大新令牌数(Max New Tokens):
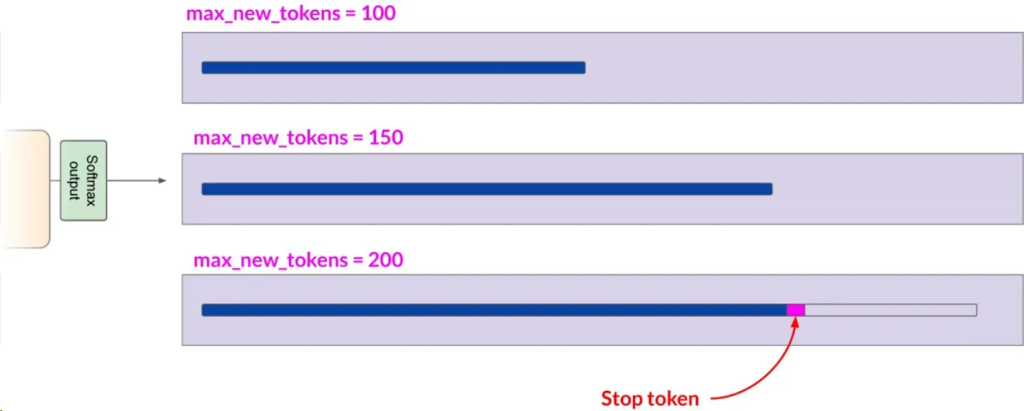
- 这个参数限制模型生成的令牌数量,可以看作是模型选择过程的上限。
- 例如,可以将其设置为100、150或200。但生成的文本长度可能因达到其他停止条件(如模型预测到序列结束符)而短于最大令牌数。
贪婪解码(Greedy Decoding):
- 默认情况下,大多数LLM使用贪婪解码,即总是选择概率最高的词。
- 这种方法适用于短文本生成,但可能导致词汇重复或词序重复。
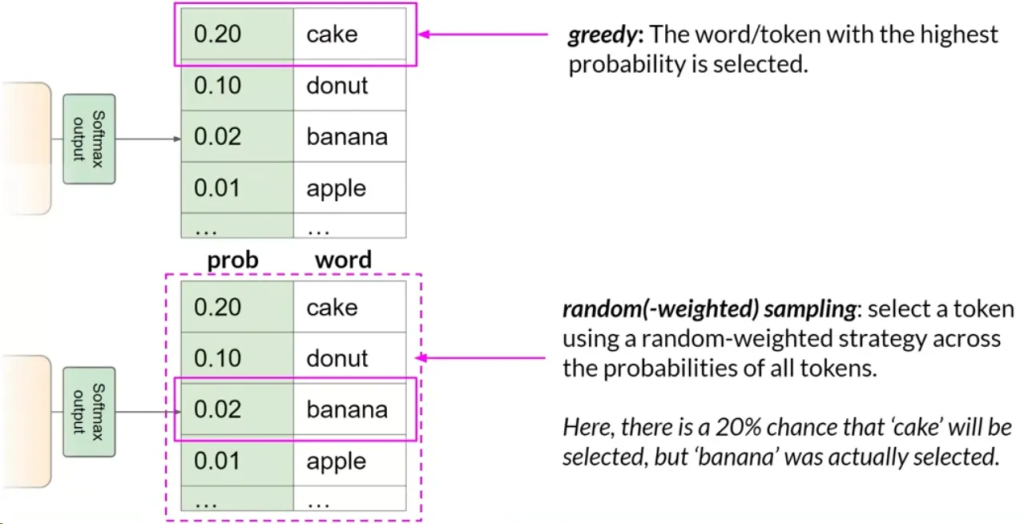
随机采样(Random Sampling):
- 引入变化性的简单方法。模型根据概率分布随机选择输出词而不是总是选择最有可能的词.
- 这种方法减少了词汇重复可能性,但设置不当可能导致生成内容偏离主题或产生无意义词.
Top K 采样:
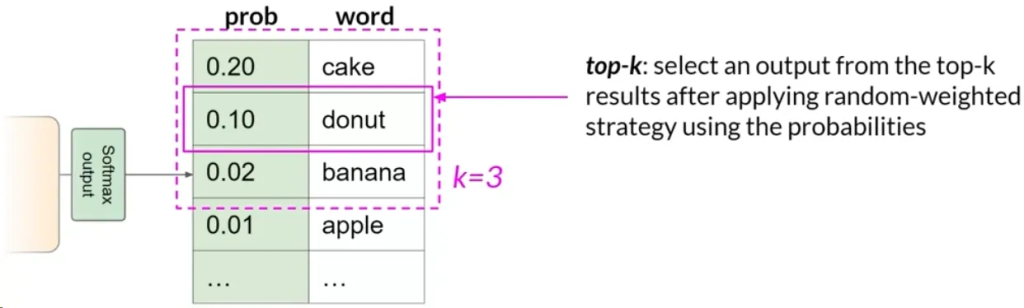
- 限制模型仅从概率最高的K个令牌中选择。例如K设置为3,则模型只从这三个选项中选择.
- 这种方法在引入一定随机性的同时,避免选择极不可能的词,使生成的文本更合理。
Top P 采样:
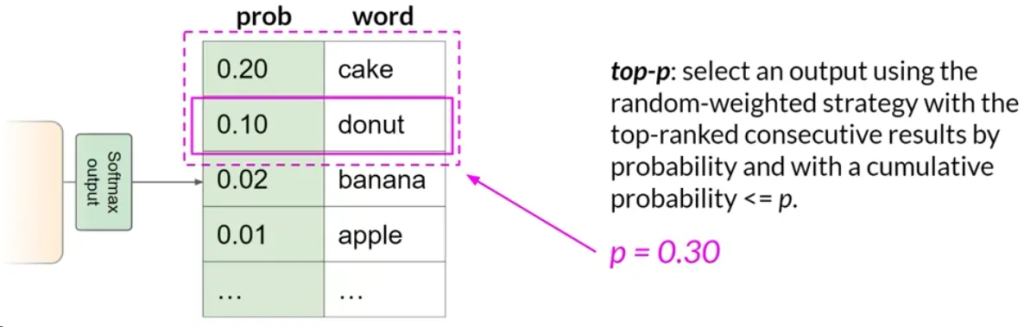
- 将随机采样限制在其组合概率不超过P的预测中。例如,如果P设置为0.3,模型将从概率为0.2和0.1的选项中选择。
- 这种方法在随机性和合理性之间取得平衡。
温度(Temperature):
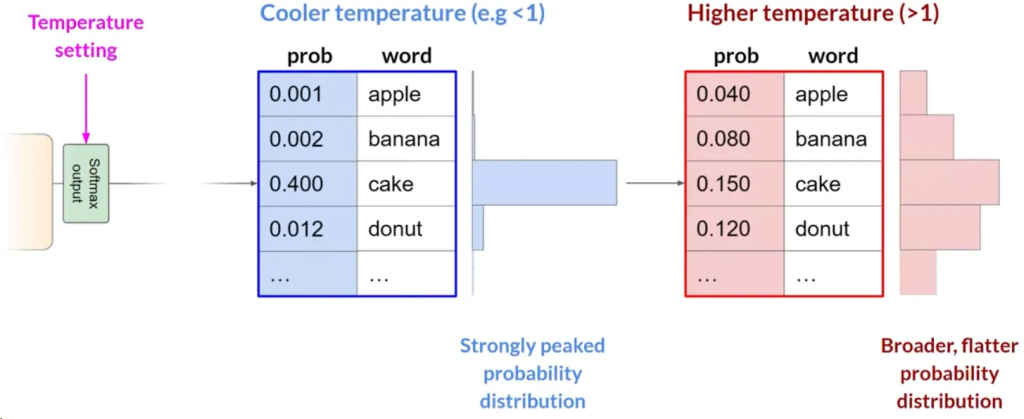
- 影响模型计算下一令牌概率分布的形状。温度越高,随机性越大;温度越低,随机性越小.
- 温度值是在模型的最终softmax层内应用的缩放因子,影响下一个令牌的概率分布的形状。