大型语言模型的挑战与解决方案 (Using the LLM in applications)
黎 浩然/ 26 11 月, 2023/ 大语言模型/LARGELANGUAGEMODEL/LLM, 机器学习/MACHINELEARNING, 研究生/POSTGRADUATE, 计算机/COMPUTER/ 0 comments
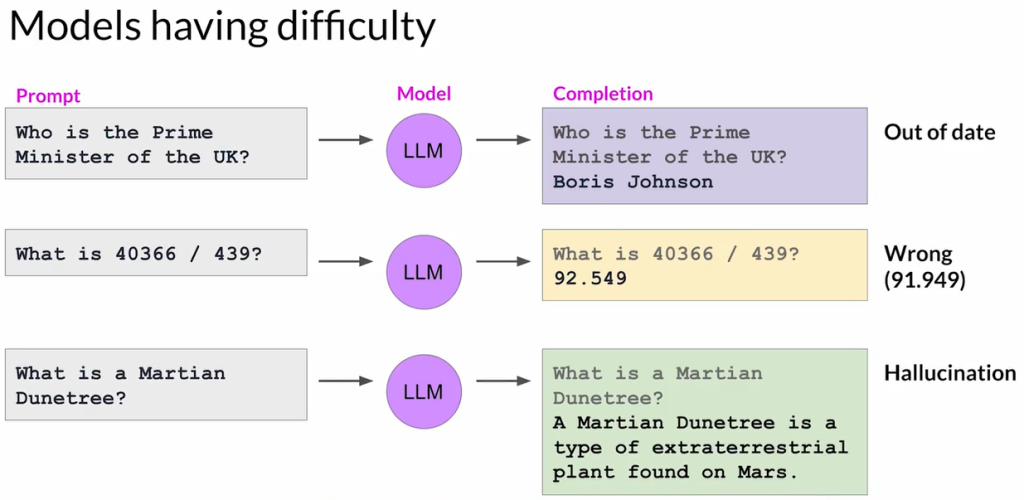
LLM的主要局限性
- 知识截止时间:
- LLM的内部知识仅限于其训练截止时间之前的数据。
- 示例:一个在2022年末之前训练的模型可能错误地认为鲍里斯·约翰逊仍是英国首相。
- 复杂数学运算:
- LLM并不执行真实的数学计算,而是预测下一个最可能的词元,可能导致不准确。
- 示例:除法等复杂数学问题可能得到近似但不正确的答案。
- 幻觉问题(Hallucination):
- 当模型缺乏知识时,可能会生成听起来合理但实际上错误或虚构的信息。
- 示例:描述一个并不存在的实体,如“火星沙丘树”。
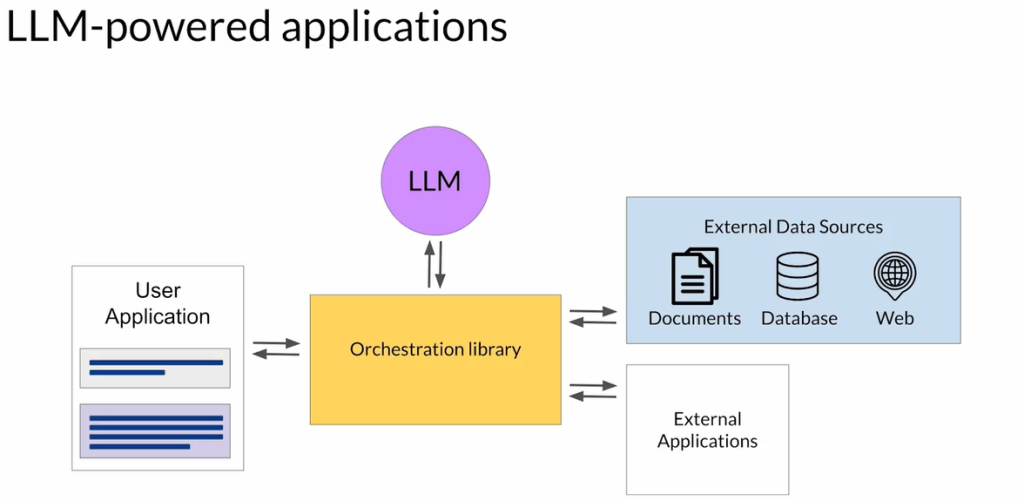
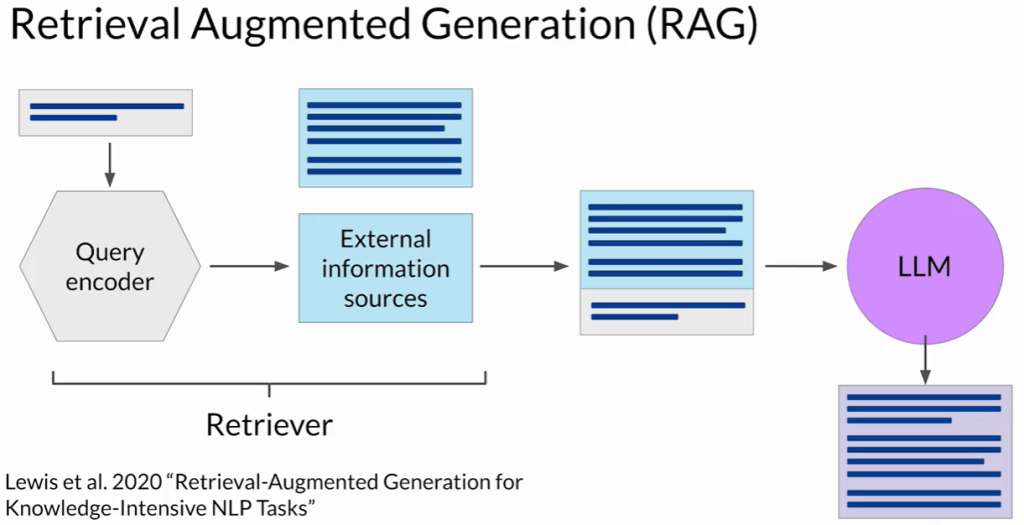
检索增强生成(RAG)
RAG概述:
- 目的:通过整合外部数据源,克服LLM的局限性。
- 优势:
- 在不进行高成本再训练的情况下,实现知识的实时更新。
- 获取原始训练数据中未包含的专有或专业知识。
RAG的工作原理:
- 主要组成部分:
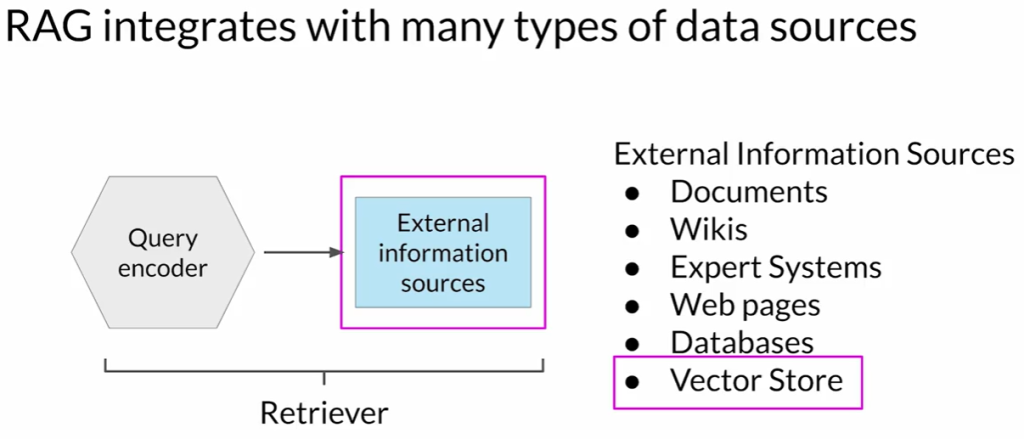
- 检索器(Retriever):由查询编码器和外部数据源组成。
- 将用户输入编码为可与外部数据匹配的查询格式。
- 基于查询检索相关文档。
- 外部数据源:可以是向量存储、SQL数据库、CSV文件等。
- 工作流程:
- 用户提示被编码并用于查询外部数据。
- 检索器找到并返回相关文档。
- 检索到的文档与原始用户提示合并。
- 扩展后的提示被传递给LLM生成更准确、相关的回答。
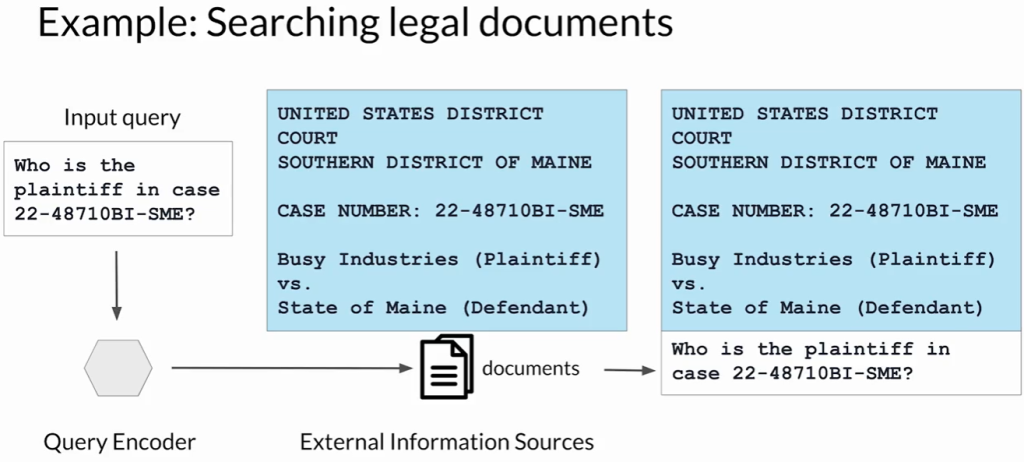
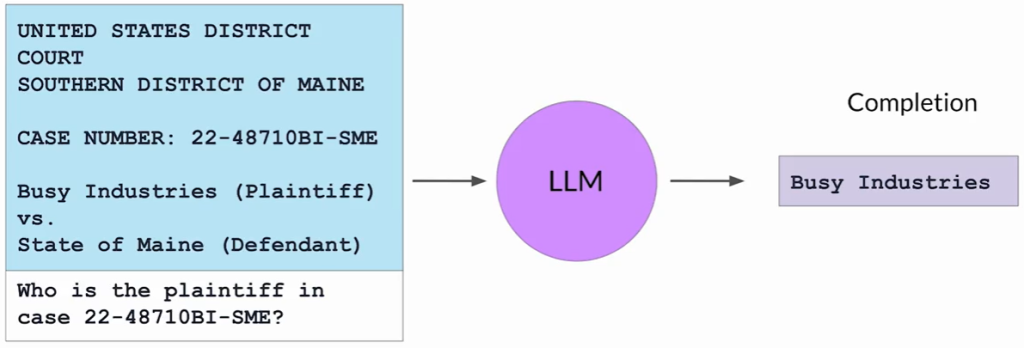
应用示例(法律案件调研):
- 律师使用RAG查询法院档案文集。
- 示例提示:询问某个案件编号中原告的相关信息。
- 流程:
- 查询编码器定位相关法律文档。
- 检索到的文本与查询合并。
- LLM根据增强后的上下文生成答案。
实际场景中的优势:
- RAG可用于总结法律文件、识别实体、提升整体文档分析效果。
外部数据集成的类型
- 本地文档库:私有数据库、内部Wiki等。
- 网络数据源:如维基百科等公共信息。
- 数据库:通过SQL查询直接访问结构化数据。
- 向量存储(Vector Stores):
- 存储文本的向量表示。
- 支持基于相似度(如余弦相似度)的快速语义检索。
实现注意事项:
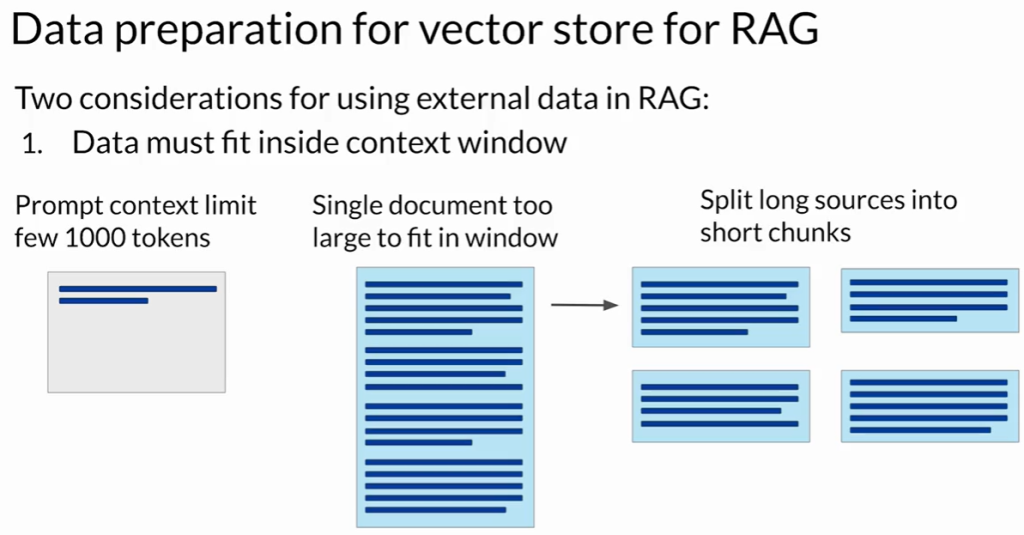
- 上下文窗口限制:
- 数据源往往超过LLM的最大上下文长度。
- 解决方案:将数据切分为更小的块。
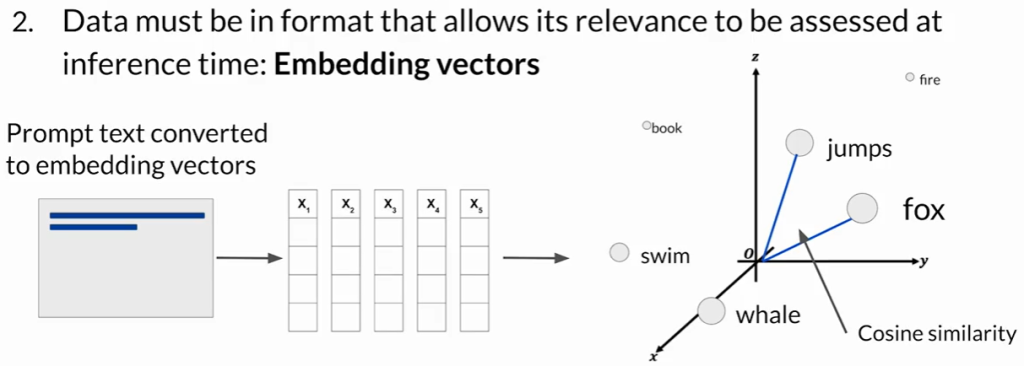
- 数据表示与检索:
- 文本需转换为嵌入向量表示(Embeddings)。
- 存入向量存储或数据库中,便于高效检索和语义匹配。
- 工具支持:
- 如Langchain等库可自动处理数据切块和嵌入流程。
RAG增强能力:
- 实时信息更新。
- 降低幻觉风险。
- 提高LLM生成内容的准确性与可靠性。
结论
- 将LLM与外部数据源连接,显著提升其实用性、准确性和可靠性。
- 下一步可以探索提升推理与规划能力的技术,以构建更强大的LLM应用。