大语言模型评估 (LLM Evaluation)
在讨论大型语言模型的评估时,本课程涉及的关键点包括:
模型评估的意义:
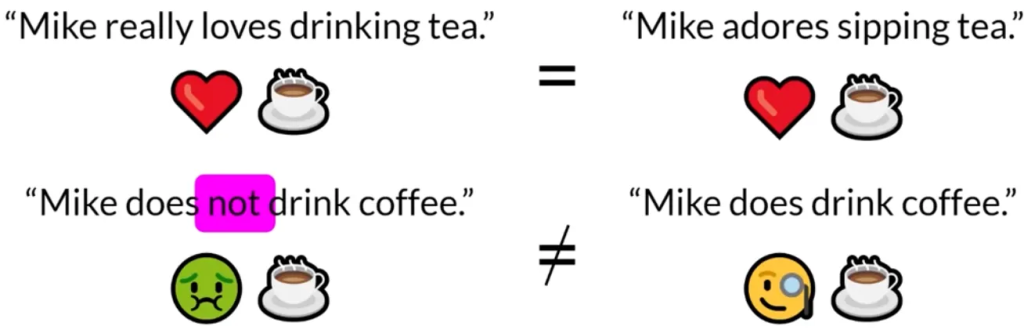
- 当提到模型在特定任务上表现良好或微调模型相比基础模型有显著改进时,这意味着模型在预定的任务上的输出质量有所提升。
- 在传统机器学习中,可以通过训练和验证数据集上的性能来评估模型,但对于输出非确定性且基于语言的大型语言模型,这种评估更具挑战性。
ROUGE 和 BLEU 评估指标:
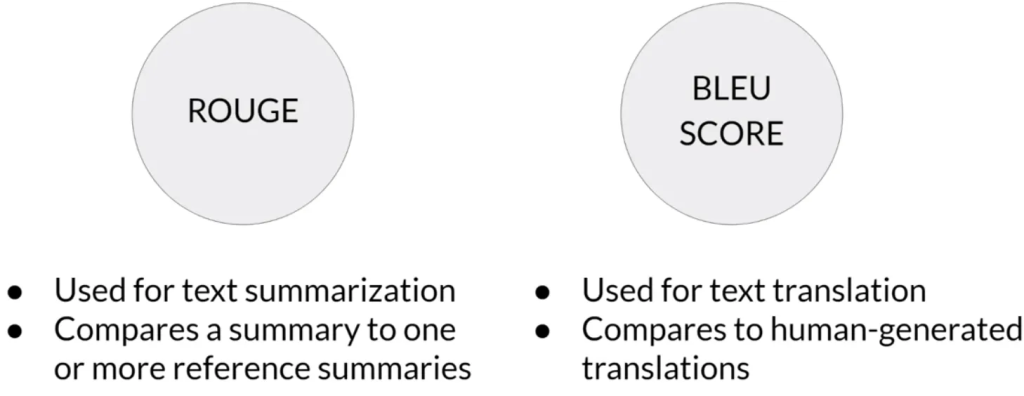
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):用于评估自动生成的摘要与人类生成的参考摘要之间的质量。它通过计算生成摘要与参考摘要之间的重叠(如单词或短语)来评估摘要的质量。


- 召回率(Recall):
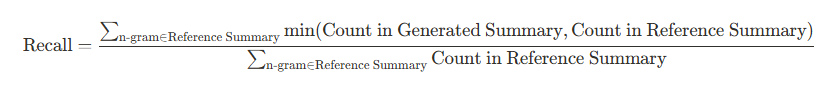
- 精确度(Precision):

- F1分数(F1 Score):
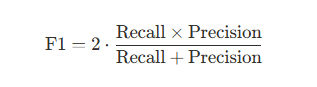
- BLEU(Bilingual Evaluation Understudy):设计用于评估机器翻译文本的质量,通过将机器生成的翻译与人类生成的翻译进行比较来计算。BLEU 分数考虑多个不同长度的 n-gram 匹配,通常从 1-gram 到 4-gram,以下是其计算方法:

- 对于每个 n-gram(For each n-gram):

- 算术平均精确度(Arithmetic Mean of Precision):
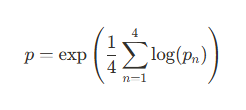
- 简洁惩罚(Brevity Penalty,BP):
- 如果候选翻译长度小于最接近的参考翻译长度,则 BP < 1;
- 如果候选翻译长度大于或等于最接近的参考翻译长度,则 BP = 1。 其中 c 是候选翻译长度,r 是参考翻译长度。

- BLEU 分数(BLEU Score):
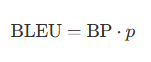
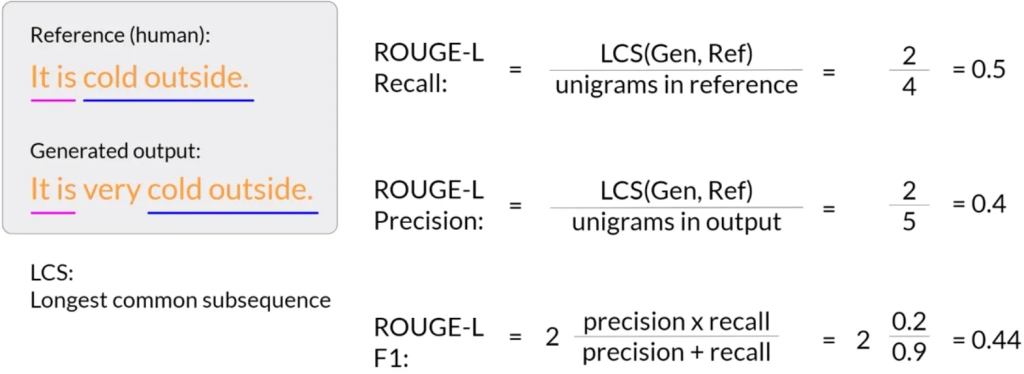
N-gram 和 最长公共子序列(LCS):

- unigram、bigram 和 n-gram 分别代表单词、两个单词的组合和 n 个单词的组合。
- ROUGE-1 使用unigram匹配来计算召回率、精确度和 F1 分数。
- ROUGE-2 考虑bigram匹配。
- 使用最长公共子序列(LCS)可以计算出更综合的评分(如Rouge-L)。
评分的局限性和挑战:
- 简单的 ROUGE 分数可能会导致不良输出获得高分,例如通过重复单词。
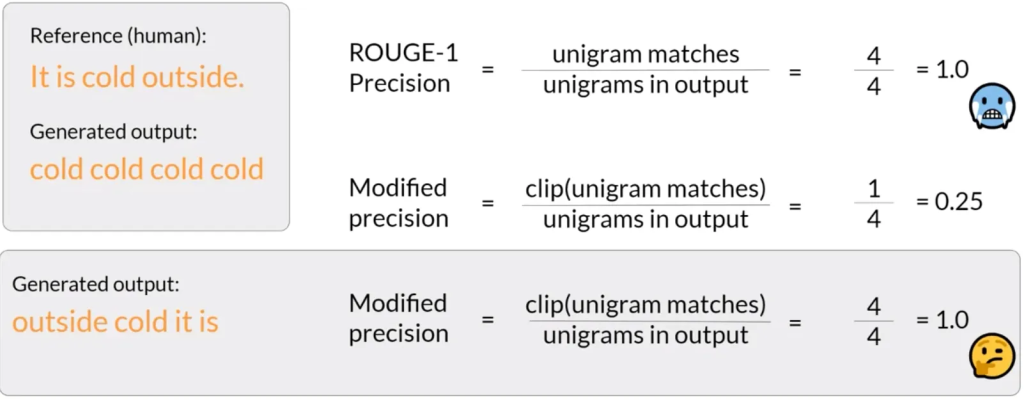
- 为了解决这个问题,可以采用修剪(clipping)功能来限制unigram匹配的数量。
- BLEU分数通过计算不同n-gram大小的平均精度来评估翻译质量。
模型性能的综合评估:
- 尽管ROUGE和BLEU是计算成本较低的简单指标,但不应单独用它们来报告大型语言模型的最终评估。
- 对于摘要任务,应使用ROUGE进行诊断性评估;对于翻译任务,应使用BLEU。
- 对于模型整体性能的评估,需要参考研究人员开发的评估基准。
大型语言模型的评估需要考虑多种指标和方法。虽然ROUGE和BLEU提供了对特定任务(如摘要和翻译)的初步评估,但局限性要求在模型整体评估中结合更全面的基准和方法.