低秩适配 (PEFT techniques 1: LoRA)
低秩适应(Low-Rank Adaptation,简称 LoRA)是一种参数高效微调(PEFT)技术,属于重参数化方法类别。下面详细解释和总结 LoRA 的工作原理和应用:
LoRA 的工作原理
- Transformer:

- LoRA 是在 Transformer 架构中应用的。
- 输入提示转换为tokens,再转换为embedding vectors,传递给encoder和/或decoder。
自注意力和前馈网络:
- Transformer中包含自注意力(self-attention)和前馈网络(feedforward networks),它们的权重在预训练期间学习得到。
LoRA 的实现:
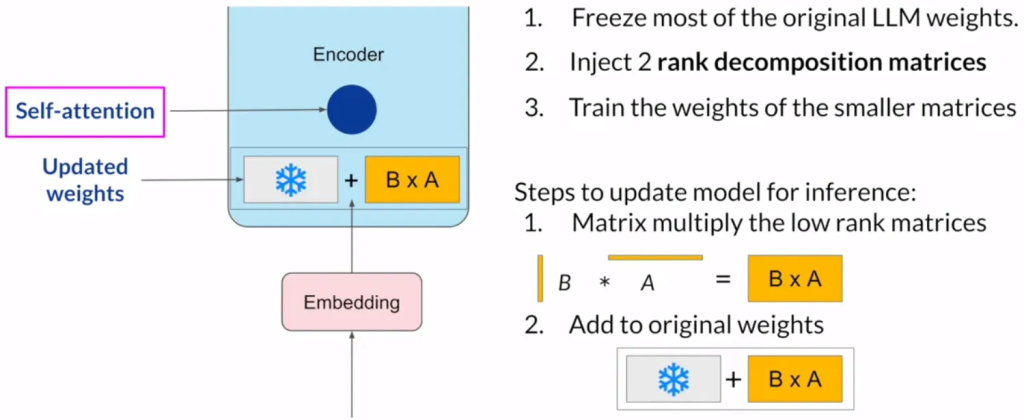
- 在微调期间,LoRA 通过冻结原始模型参数,并在原始权重旁注入一对低秩分解矩阵(rank decomposition matrices),减少了需训练的参数数量。
- 这些较小的矩阵的维度设置为使它们的乘积与被修改权重的维度相同。
微调和推理过程:
- 在推理时,这两个低秩矩阵相乘,产生与冻结权重同维度的矩阵。
- 将此矩阵加到原始权重上,并在模型中用这些更新后的值替换原始权重。
LoRA 的应用和优势
节省参数和计算资源:
- LoRA 显著减少可训练参数数量,通常可在单个 GPU 上执行,无需分布式 GPU 集群。
- 适用于多任务微调,可以为每个任务微调不同的低秩矩阵组,然后在推理时切换。
模型性能:
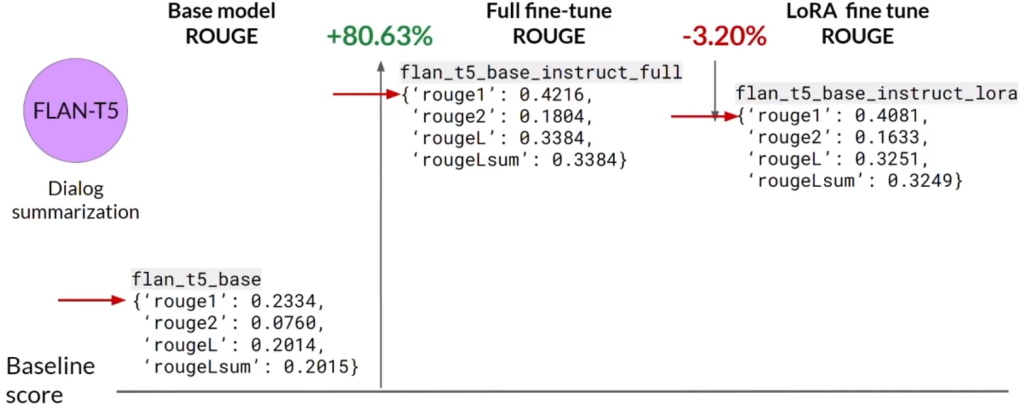
- 使用 LoRA 微调的模型性能与原始基础模型和全量微调版本相比表现良好。
- 尽管 LoRA 微调的性能略低于全量微调,但使用的计算资源显著更少,因此这种小幅的性能折衷可能是值得的。
LoRA 矩阵的 Rank 选择:
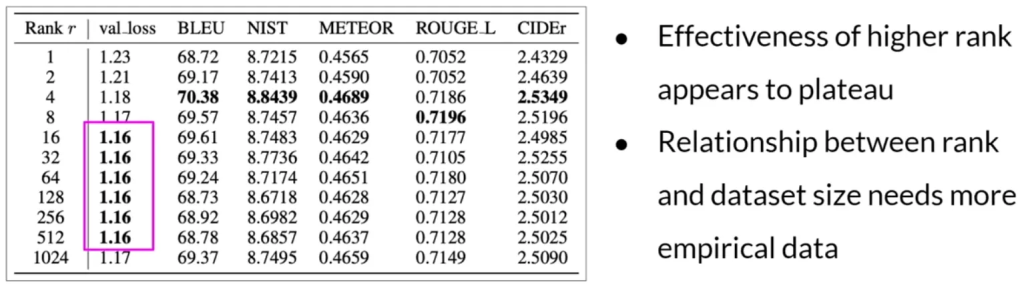
- 选择 LoRA 矩阵的 Rank 是一个活跃的研究领域。
- 排名在4-32的范围内可以提供减少可训练参数与保持性能之间的良好折衷。
总结
LoRA作为一种PEFT方法,通过在模型中引入低秩矩阵,有效减少了微调过程中需要训练的参数数量。这种方法使得微调大型语言模型在资源受限的环境中成为可能,同时在多任务微调场景中显著降低了存储和计算成本。尽管 LoRA 微调的模型可能在性能上略逊于全量微调的模型,但在计算资源和训练效率方面的优势使其成为一种有吸引力的选择。