预训练大语言模型 (Pre-training large language models)
预训练大型语言模型(LLM)的过程涉及以下几个关键步骤:
选择模型

- 选择工作的模型,可以是现有的模型或从头开始训练的模型。
开发应用
- 使用现有基础模型来开发应用,这些模型通常是开源的,并在AI社区中可用。
模型卡片
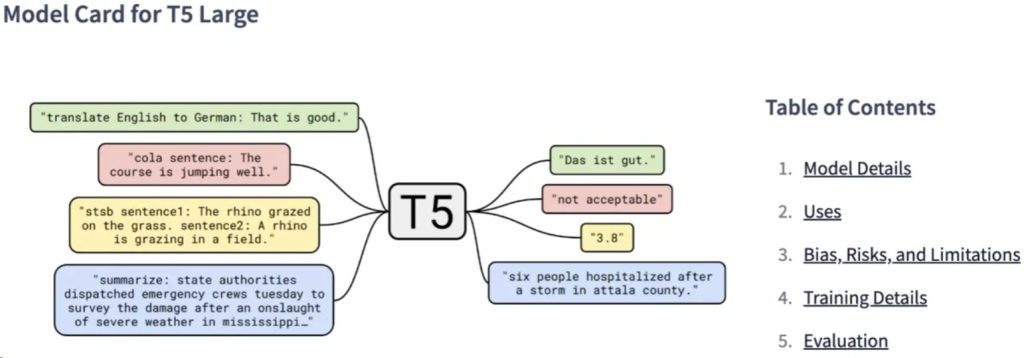
Model Card for T5 Large
- 模型卡片描述了每个模型的最佳用例、训练方式和已知限制。
模型选择
- 根据任务需求选择合适的变体,这些变体因训练方式不同而适用于不同的语言任务。
预训练阶段
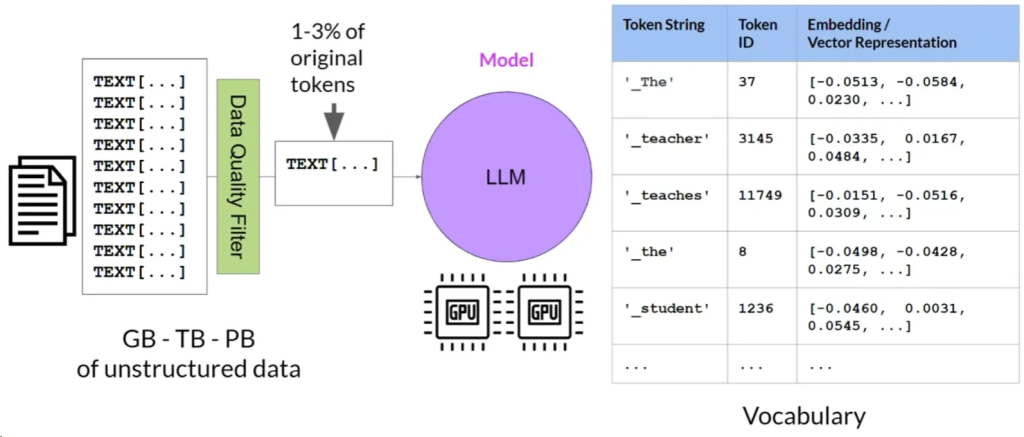
- LLM在预训练阶段通过学习大量非结构化文本数据来编码深层的语言统计表征。
- 这些数据可能是从互联网或特定语言模型训练集中抓取的。
数据处理
- 需要处理抓取的数据以提高质量、解决偏见问题、去除有害内容。
不同的变体
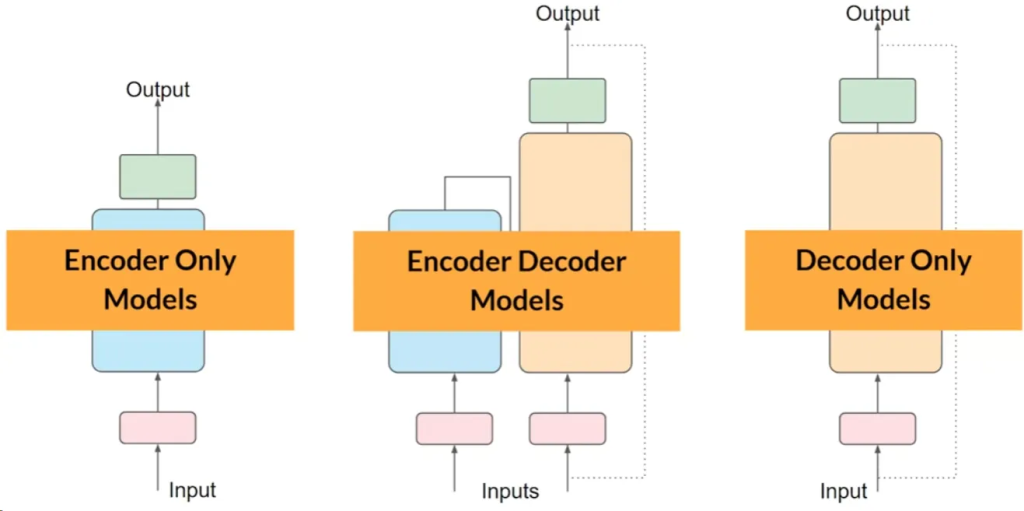
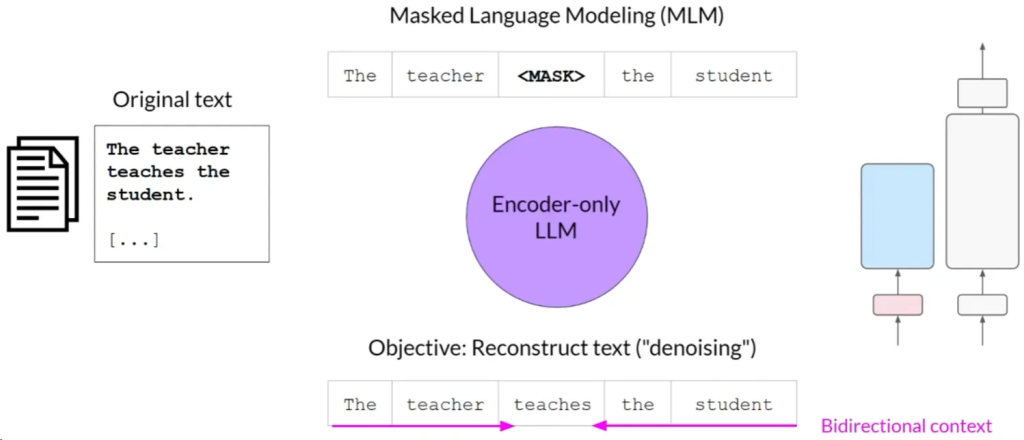
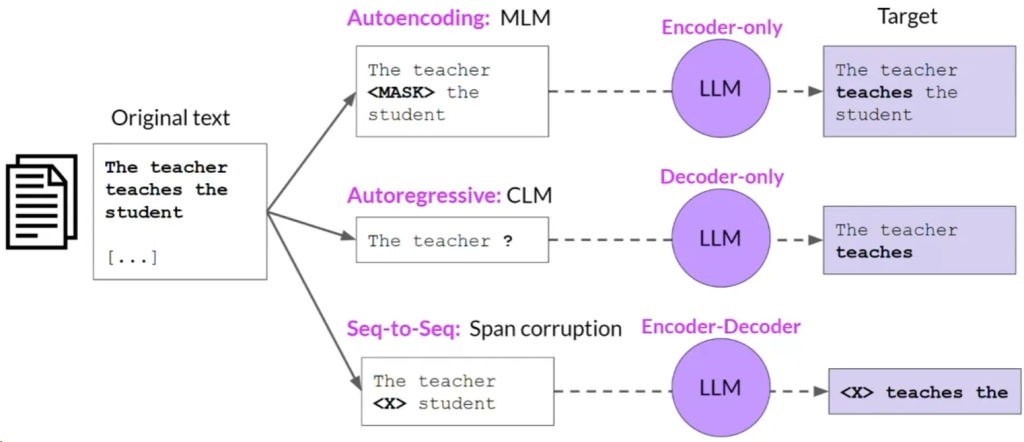
- 仅编码器模型(Autoencoding):使用MLM进行预训练,适用于句子分类和令牌级任务(例如BERT和RoBERTa)。

- 仅解码器模型(Autoregressive):使用CLM进行预训练,通常用于文本生成(例如GPT和BLOOM)。
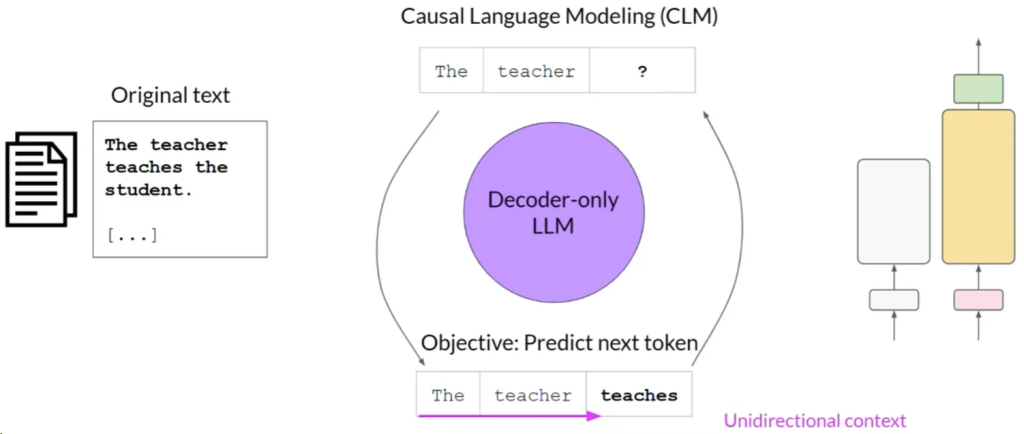

- 序列到序列模型(Sequence-to-Sequence):用编码器和解码器部分,预训练目标各异,适用于翻译、摘要和问答(例如T5和BART)。
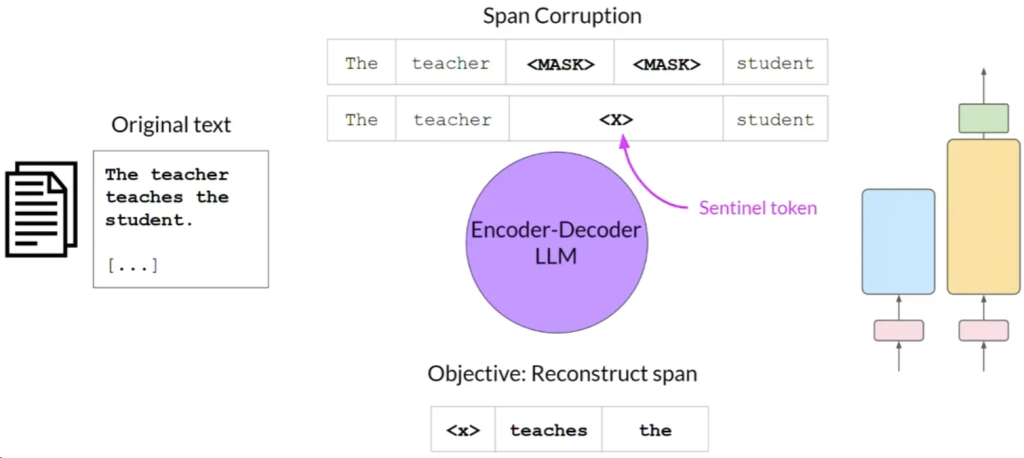

遮蔽输入令牌的随机序列。这些被遮蔽的序列随后会被一个独特的哨兵令牌(Sentinel token)所替换,如这里所示为x。哨兵令牌是添加到词汇表中的特殊令牌,但并不对应于输入文本中的任何实际单词。解码器的任务是自回归地重构被遮蔽的令牌序列。
模型规模
- 更大的模型通常更能有效地执行任务,无需额外的上下文学习或进一步训练。
模型增长的挑战
- 训练大型模型既困难又昂贵,可能无法持续训练越来越大的模型。
大型模型的趋势
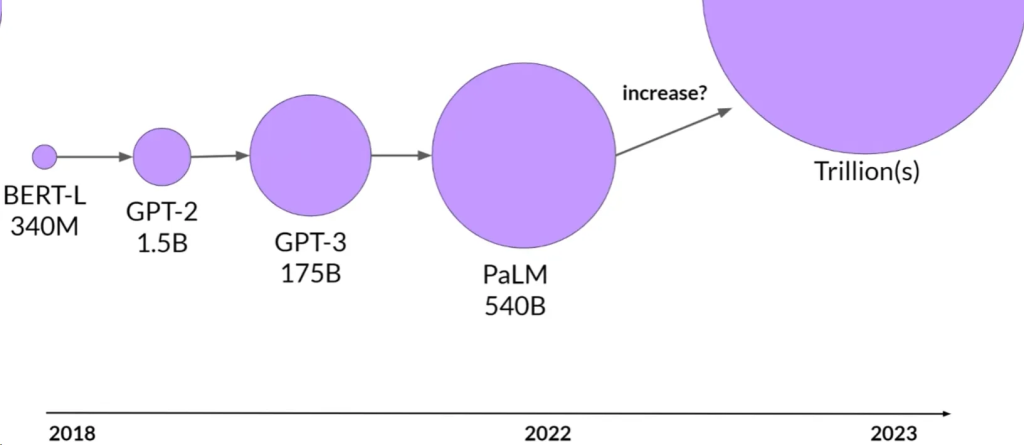
- 大型模型的发展受到转换器架构的可扩展性、大量数据训练的可用性和强大计算资源的发展的推动。
预训练大型语言模型是一个复杂的过程,涉及选择合适的模型架构,处理和使用大量数据,以及考虑在应用开发中的实际使用场景。尽管存在挑战,但预训练模型在理解和生成语言方面展示了显著的能力。