循环神经网络 (Recurrent Neural Network, RNN)
$$ \begin{equation}\begin{split}a^{<t>}=g(W_{aa}a^{<t-1>}+W_{ax}x^{<t>}+b_a)&=g(W_a[a^{<t-1>},x^{<t>}]+b_a)\\\\ \text{s.t.}\space W_a=[W_{aa},W_{ax}], [a^{<t-1>},x^{<t>}]&=[{a^{<t-1>}\over x^{<t>}}]\end{split}\end{equation} $$
$$ \begin{equation}\hat{y}=g(W_{ya}a^{<t>}+b_y)=g(W_{y}a^{<t>}+b_y)\end{equation} $$
递归神经网络(Recurrent Neural Network),是一种专为处理序列数据而设计的神经网络。
与传统前馈神经网络(如多层感知机)不同,RNN可使用其内部状态来处理变长序列输入。
下面是一些RNN的基本特点:
- 序列处理:RNN被设计用来处理序列数据,如时间序列、文本、语音等。
- 内部状态:RNN具有内部状态,该状态在处理序列的每个时间步都会更新,使得RNN可以记住前面的信息,并用于后续的计算。
- 参数共享:在处理序列的每个时间步时,RNN 使用相同的权重。这与传统的前馈神经网络不同,后者对于每个输入层都有独立的权重。
- 递归结构:RNN的这个名字来源于它的结构:网络可以被看作是多个相同的层叠加在一起,其中每一层都接收前一层的输出(或状态)作为输入。
尽管RNN理论上可以捕获长序列中的依赖关系,但在实践中,它们往往难以学习长期的依赖。这是由于所谓的“梯度消失”和“梯度爆炸”问题。为了解决这些问题,研究者们提出了更复杂的RNN变体,如长短时记忆网络(LSTM)和门控循环单元(GRU)。以下是RNN的简化图示:
+-------+ +-------+ +-------+
| | | | | |
| RNN | | RNN | | RNN |
| | | | | |
+-------+ +-------+ +-------+
| ^ | ^ | ^
v | v | v |
xt ht-1 xt+1 ht xt+2 ht+1
其中,xt 是在时间 t 的输入,ht 是在时间 t 的内部状态或“隐藏状态”。
隐藏状态计算
在最基础的RNN中,隐藏状态 $h_t$ 的计算通常基于前一个隐藏状态 $h_t$ 和当前时间步的输入 $x_t$。具体的计算公式如下:
$$ \begin{equation}h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h)\end{equation} $$
其中:
- $W_{hh}$和 $W_{xh}$ 是权重矩阵。
- $b_h$ 是偏置项。
- tanh 是双曲正切激活函数。
- 输入到隐藏:$W_{xh} x_t$ 表示当前输入 $x_t$ 与其权重矩阵 $W_{xh}$ 的乘积。
- 隐藏到隐藏:$W_{hh} h_{t-1}$ 表示前一个隐藏状态 $h_{t-1}$ 与其权重矩阵 $W_{hh}$ 的乘积。
- 这两个乘积结果加在一起,然后再加上偏置项 $b_h$。
- 最后,将结果通过双曲正切激活函数 anh ,以确保输出值在 -1 和 1 之间
各种类型RNN

- 一对一 (One-to-One)
- RNN与传统的神经网络没有太大区别。输入和输出都是固定大小,不涉及序列。
- 例子:标准神经网络中的常规任务。
- 一对多 (One-to-Many)
- 输入是一个固定大小的数据,输出是一个序列。
- 例子:音乐生成。输入可能是音乐类型或第一个音符,输出是一系列音符组成的片段。
- 多对一 (Many-to-One)
- 输入是一个序列,输出是固定大小的数据。
- 例子:情感分类。例如,输入是一段电影评论的文本,输出是一个评分或情感标签。
- 多对多 (Many-to-Many)
- 输入和输出都是序列。
- 例子:命名实体识别。在这种情况下输入序列(词)和输出序列(标签)的长度相同。
- 多对多 (输入输出长度不同的版本)
- 输入和输出都是序列,但它们的长度可以不同。
- 例子:机器翻译。例如,输入可能是一个法语句子,输出是其英语翻译。由于语言结构差异,输入和输出句子的长度可能不同。
- 这种架构通常分为两部分:编码器(读取输入序列)和解码器(产生输出序列)。
- 基于注意力的架构 (Attention-based Architectures)
- 这种架构考虑了输入序列中的不同部分对输出的重要性。
RNN模型训练
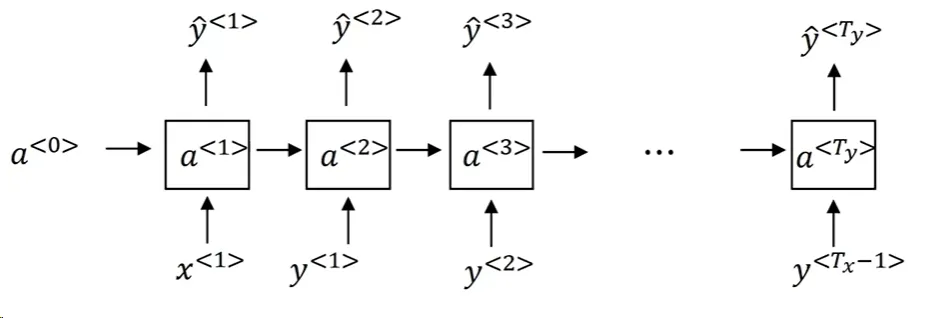
- 目标:语言模型的基本任务是给定一个句子,估计这个句子的概率。
目的:语言模型的目的是为语言中可能出现的每个句子或词序列赋予一个概率。这个概率表示在真实世界中,这个句子或词序列出现的可能性有多大。
计算:考虑句子 “我喜欢吃苹果”。语言模型会估计句子开始后 “我” 出现的概率,接着是在 “我” 之后 “喜欢” 出现的概率,以此类推。所有这些条件概率乘积就是整个句子概率。
意义:考虑语音识别的情境。假设你说了一个句子,由于噪音或发音不清,系统可能对你说的话有多种解释。语言模型可以帮助系统确定哪个解释在实际语境中更可能是正确的。
- 训练集准备:
- 使用大量的文本数据(称为语料库)作为训练集。
- 对句子进行标记化,将每个单词映射到一个独热向量或词汇表中的索引。
- 可以添加一个EOS(句子结束)标记,表示句子的结束。
- 如果某些单词不在词汇表中,可以使用一个特殊的“UNK”标记来代替这些单词。
- 建立RNN模型:
- 输入:一系列单词(或单词的独热向量)。在时间步 t ,输入 xt 是前一时间步输出,即 xt = yt-1。
- 输出:下一个单词的概率分布。
- 每个时间步使用 Softmax 进行预测,输出整个词汇表中每个单词的概率。
- 模型从左到右,一个词接一个词地进行预测。
- 损失函数:
- 在每个时间步 t ,使用Softmax损失函数计算真实单词 yt 和模型预测 \hat{y}t 之间的损失。
- 总损失是所有时间步的损失之和。
- 训练:使用大型训练集训练RNN。经过训练后,模型可以给定一系列单词,并预测下一个单词的概率。
- 句子概率的计算:给定一个新句子,可以通过乘以每个单词的概率来计算整个句子概率。
一旦模型被训练,不仅可以用于评估句子的概率,还可以用于生成新的句子,这是通过从模型中采样序列来完成的。
对新序列采样 (Sampling Novel Sequences)
RNN(循环神经网络)中的Sampling Novel Sequences是指使用训练好的 RNN模型生成新的、未见过的序列。以下是其流程的总结:
- 初始化:开始时,通常设置 x1 = 0 和 a0 = 0 作为输入。
- 采样第一个词:
- 使用Softmax层计算模型预测的概率分布。
- 根据这个概率分布随机采样一个词作为第一个输出词。
- 连续采样:
- 对于接下来的每一个时间步,将上一步采样得到的词作为输入。
- 再次使用Softmax层计算模型预测的概率分布。
- 根据这个概率分布随机采样下一个词。
- 结束条件:
- 如果模型的词汇表中包含了一个句子结束(End of Sentence, EOS)标记,那么当模型采样到这个标记时,就可以停止采样。
- 或者,可以预先设置一个句子的最大长度,当达到这个长度时停止采样。
- 处理未知词:
- 如果模型采样到一个“未知词”标记,有两种处理方式:
- 可以重新采样,直到得到一个非未知词。
- 或者,可以直接将“未知词”标记包含在输出中。
- 如果模型采样到一个“未知词”标记,有两种处理方式:
- 字符级RNN vs 词级RNN:
- 上述过程描述的是词级RNN,但也可以使用字符级RNN来采样。
- 字符级RNN的词汇表包括单个字符,如字母、数字、空格和标点符号。
- 使用字符级RNN,输出序列的每一个元素都是一个字符,而不是一个词。
- 输出:模型生成的序列反映了其在训练数据上学到的结构和模式。
总的来说,Sampling Novel Sequences的过程是一种从训练好的RNN语言模型生成新句子或序列的方法,这些新句子在结构和模式上与训练数据相似,但是是全新生成的。