扩展规律与计算最优模型 (Scaling laws and compute-optimal models)
这段文字详细探讨了大型语言模型(LLM)的训练过程中涉及的关键因素,特别是模型大小、训练配置、性能之间的关系,以及如何根据计算预算优化这些参数。以下是对这些内容的详细解释和总结:
模型性能与大小的关系:
- 训练大型语言模型的主要目标是最小化预测令牌时的损失,从而提高模型性能。
- 改善性能的两种方法是增加训练数据集的大小和模型中的参数数量。理论上,可以通过扩展这两个因素来提高性能。
计算预算的考虑:

Compte budget for training LLMs
- 在训练模型时需要考虑的一个重要因素是计算预算,包括可用GPU数量和训练时间。
- 引入了“petaFLOP/s-day”(petaFLOP per second day)的计算单位量化所需的资源。
模型大小与计算需求:

Number of petaflop/s-days to pre-train various LLMs
- 不同大小的模型(如BERT、RoBERTa、T5和GPT-3)需要不同的计算资源。
- 例如,T5 XL(3B)需要约100 petaFLOP/s-day,而最大的GPT-3模型(175B参数)需要约3700 petaFLOP/s-day。
性能与计算预算的关系:
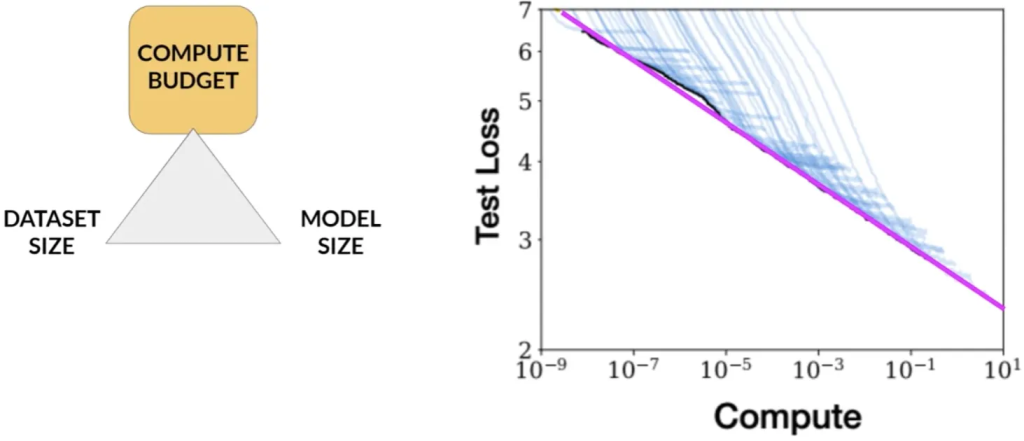
Compute budget vs. model Performance
研究显示,模型性能与计算预算之间存在明确的关系,可以通过幂律关系来近似。
这表明,增加计算预算可以提高模型性能,但实际上,可用的计算资源通常是有限的。
训练数据集大小与模型参数:

Dataset size and model size vs. performance
- OpenAI的研究者发现,训练数据集的大小和模型中的参数数量也遵循幂律关系。
- 例如,对于具有700亿参数的模型,理想的训练数据集应包含1.4万亿个令牌。
Chinchilla研究和计算最优模型:
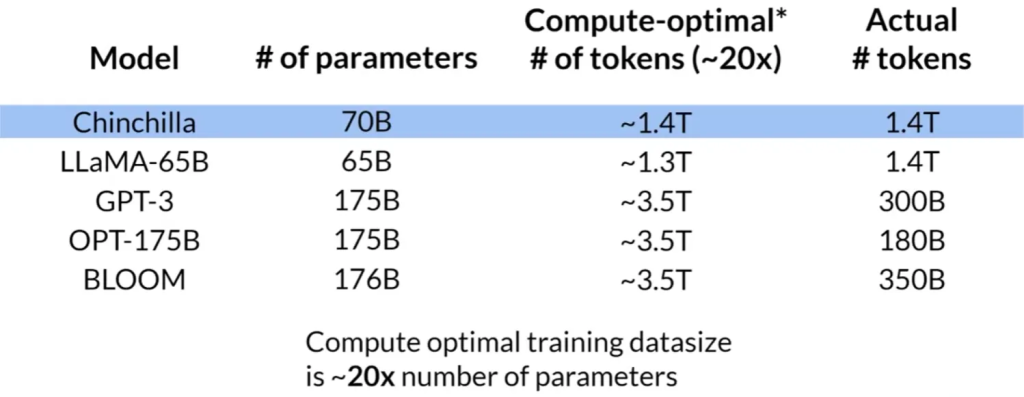
Chinchilla scaling laws for model and dataset size
- Chinchilla研究指出许多大型模型(如GPT-3)可能过度参数过多而训练不足。
- 研究建议,对于给定的计算预算,较小的模型如果在更大的数据集上训练,可能会达到与更大模型相同的性能。
未来趋势:
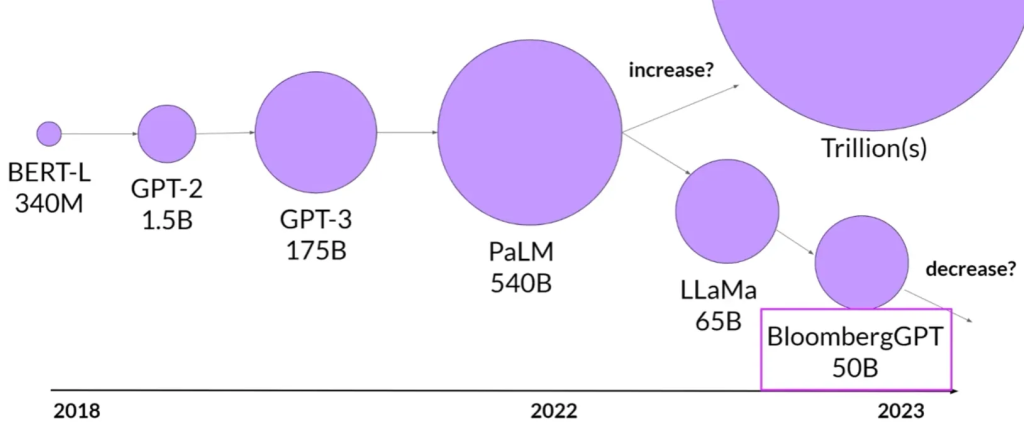
Model size vs. time
预计未来会有更多团队或开发者优化他们的模型设计,不再单纯追求更大的模型,而是寻找性能和计算效率之间的平衡。
这些发现对于理解大型语言模型的训练和性能提升具有重要意义,特别是在有限的计算资源下如何最有效地提升模型性能。