自注意力 (Self-Attention)
目标:自注意力的目的是为序列中的每个单词生成一个新的表示,这个表示考虑到了上下文中其他单词对当前单词的影响。
查询、键和值:为实现这目的,每个单词都与三个向量相关联,即查询(Query)、键(Key)和值(Value)。这些向量是通过学习到的权重矩阵与单词的嵌入 (embedding) 相乘计算。
- 查询向量代表了一个问题。
- 键向量帮助我们确定其他单词与当前单词查询的相似度或关联性。
- 值向量表示该单词的实际信息或内容。
- 每个单词嵌入(embedding)是 x<i>。对于第 i 个单词:
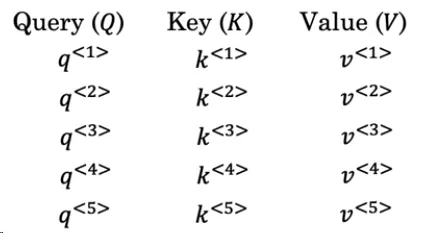
\begin{equation}\begin{aligned} \left\{ \begin{array}{ll} q^{<i>} = W^Q \times x^{<i>} \\ k^{<i>} = W^K \times x^{<i>} \\ v^{<i>} = W^V \times x^{<i>} \end{array} \right. \end{aligned}\end{equation}
其中,$W^Q$、$W^K$ 和 $W^V$ 是学习得到的权重矩阵。对于$x^{<i>}$,其注意力向量:
$$ \begin{equation}A(q,K,V)={\sum_i{\exp{(q\cdot k^{<i>}) } \over {\sum_j \exp{(q\cdot k^{<j>}})} }v^{<i>}}\end{equation} $$
注意到${\exp{(q\cdot k^{<i>}) } \over {\sum_j \exp{(q\cdot k^{<j>}})} }$与前面提到的$\alpha_{t, t’} = \frac{\exp(e_{t, t’})}{\sum_{t”} \exp(e_{t, t”})}$比较相似。可以理解为
$$ \begin{equation}A(q,K,V)={\sum_i{\exp{(q\cdot k^{<i>}) } \over {\sum_j \exp{(q\cdot k^{<j>}})} }v^{<i>}}={\sum_i{ \alpha_{,i} }\cdot v^{<i>}=C}\end{equation} $$
每行输入的注意力向量构成注意力矩阵(在前面的Attention Model中并没有QKV的概念)。
注意力矩阵
Attention机制详解(二)——Self-Attention与Transformer
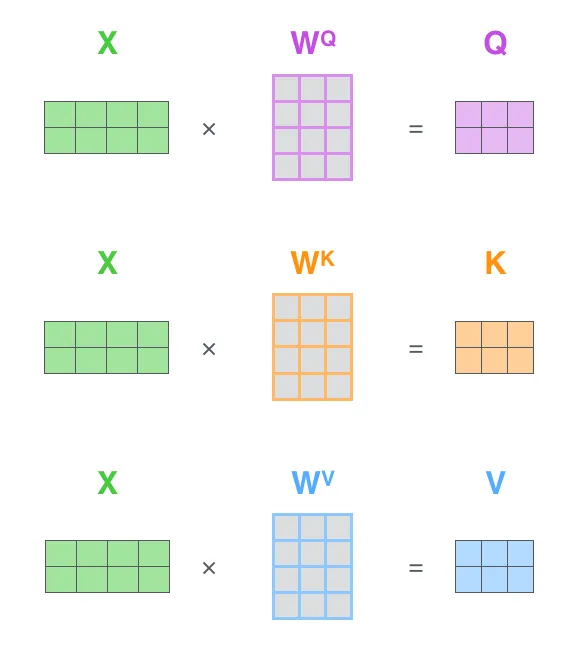
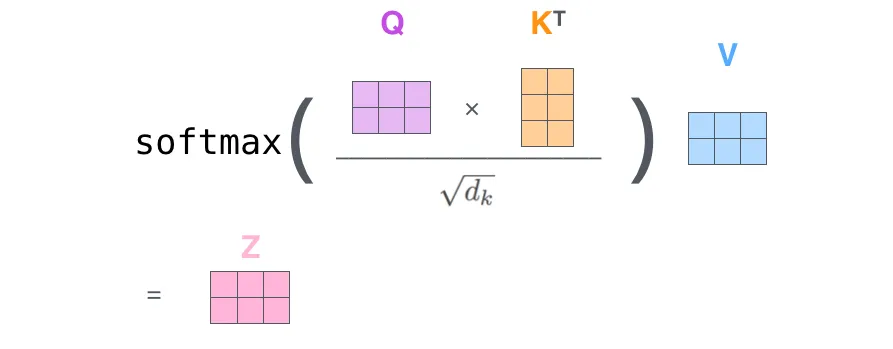
对于左图中的X,每行表示一个输入$x^{<i>}$。每个$x^{<i>}$ 是一个维度为4的一维嵌入向量。
因此Q、K、V矩阵的每行也表示每个$x^{<i>}$所对应的$q^{<i>}$、$k^{<i>}$、$v^{<i>}$向量。在上述例子中$Q\times K^{T}$得到2×2的矩阵;对该矩阵的元素$Q\times K^{T}[i][j]$表示第j个单词对单词i的影响。即$q^{<i>}\cdot k^{<j>}=Q\times K^{T}[i][j]$.
对22式进行缩放,得到缩放点积注意力:
$$ \begin{equation}A(Q,K,V) =softmax\Big({QK^T\over\sqrt{d_k}}\Big)V \end{equation} $$
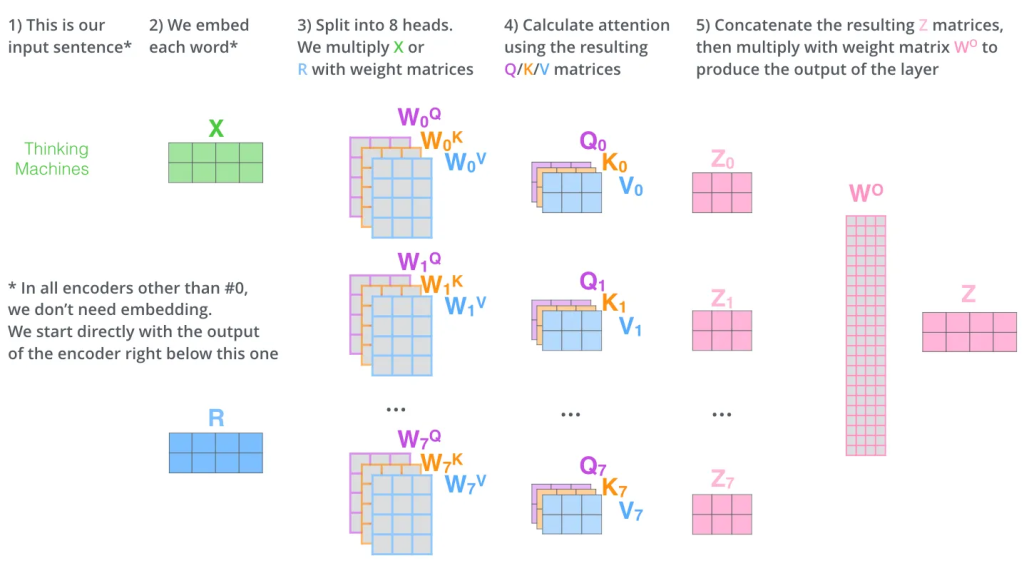
多头注意力
Z_0.shape = … = Z_7.shape = (2, 3); concat(Z_0, …, Z_7).shape = (2, 24)
多头注意力(Multi-Head Attention)是自注意力机制的一个扩展,它能够帮助模型从不同的表示子空间捕捉到序列中的不同方面的信息。以下是该机制的主要思想和工作方式的简要总结:
核心思想:多头注意力本质上是对自注意力机制的重复执行。
不同的权重矩阵:在每个头中,使用不同的权重矩阵$W^i_Q$,$W^i_K$, 和$W^i_V$来计算查询、键和值向量。这意味着每个头都会关注输入的不同方面。
并行计算:尽管可以认为这些“头”是顺序执行的,但实际上,由于每个头的计算都是独立的,因此可以并行计算所有头。
结果合并:完成多头注意力后每个头的输出会被拼接在一起,并乘以一个额外的权重矩阵$W^O$以得到最终的输出。
Transformer
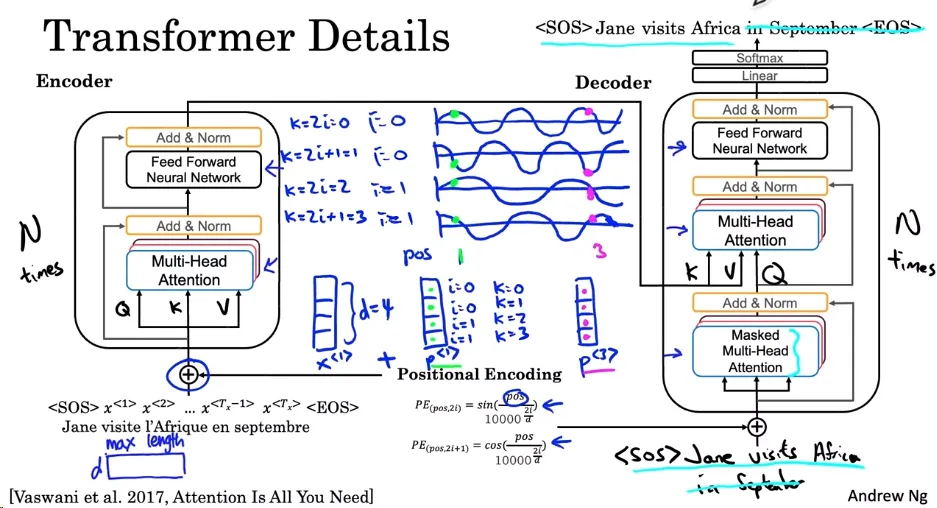
Transformer 是一种深度学习模型,特别适用于处理序列数据,如时间序列或自然语言文本。Transformer 由“Attention Is All You Need”这篇论文首次提出,并已成为许多现代 NLP 任务的基础,例如 BERT 和 GPT。 Transformer 的主要组成部分和特点:
组成:Transformer 由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。
编码器:
- 输入是一个序列,例如一个句子。
- 每个输入都被转化为一个向量表示(通常称为词嵌入或 embeddings)。
- 这些词嵌入经过一系列的编码器块处理,每个块包含多头注意力机制和前馈神经网络。
- 这些块可以重复多次(通常为 6 次)。
解码器:
- 以编码器的输出和另一个序列为输入。
- 这些输入经过一系列的解码器块,每个块也包含多头注意力机制和前馈神经网络。
- 解码器块也可以重复多次。
多头注意力:
$$ \begin{equation}\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V\end{equation} $$
- 其中 Q, K, 和 V 分别是查询、键和值矩阵。
- 允许模型同时关注序列中的多个位置。
- 它重复使用自注意力机制,但是每次都使用不同的权重矩阵。
位置编码: 对于位置 pos 和维度 i,位置编码为:
$$ \begin{equation}PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right)\end{equation} $$
$$ \begin{equation}PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right)\end{equation} $$
- 因为 Transformer 没有内置顺序概念,需要添加位置编码来给予序列中词以位置信息。
- 位置编码是通过 sine 和 cosine 函数计算的,并加到词嵌入中。
残差连接:编码器和解码器块都使用残差连接,有助于避免深度网络中的梯度消失问题。
标准化:Transformer 使用了与 BatchNorm 类似的 AddNorm 层,有助于加速学习。
训练时的遮蔽:训练过程中,为模仿预测时的情况,使用了Masked Multi-head Attention。