SVF – 静态值流图分析
Technical documentation
SVF(SVGA框架)的详细内部工作机制,包括内存建模、指针分析和基于其设计的值流构建。
Memory Model
SVF 解析 LLVM 位码(bit code)并为指针分析创建其内部符号表信息。我们采用 LLVM 的约定,将所有符号分为两种:ValSym 代表一个寄存器级的 LLVM 值,它是一个顶级指针;然而ObjSym 代表一个抽象内存对象(Abstract Memory Objects),它是一个指针的地址取值变量(Address-taken Variable of A Pointer)。例如代码:
; Function Attrs: noinline nounwind uwtable
define dso_local i32 @main() #0 {
entry:
%a1 = alloca i8, align 1
%b1 = alloca i8, align 1
%a = alloca i8*, align 8
%b = alloca i8*, align 8
store i8* %a1, i8** %a, align 8
store i8* %b1, i8** %b, align 8
call void @swap(i8** %a, i8** %b)
ret i32 0
}%a1、%b1、%a、%b 就是寄存器级 LLVM 值 ValSym;alloca i8, align 1 ,alloca i8*, align 1是指针的地址取值变量 ObjSym。另外一些对象被特别标记。例如那些静态上无法确定的符号会被标记为 BlackHole,如 LLVM 中的 UndefValue。常量对象被标记为 ConstantObj。
Abstract Memory Objects
每个抽象内存对象(Abstract Memory Objects,MemObj),包括全局对象、栈对象还是堆对象,都会在内存分配点(memory allocation site)处进行解析。每个对象都有其自己的类型信息,这些信息被记录在 ObjTypeInfo 中。具有结构体类型(StInfo)的对象会带有其所有字段信息(FieldInfo),包括每个字段的偏移量和类型。嵌套的结构体会被扁平化。
抽象内存对象(Abstract Memory Object,MemObj)和符号(Symbol,Val/ObjSym):
抽象内存对象(Abstract Memory Object)
- 实际内存模型:抽象内存对象(MemObj) 是对程序中实际的内存区域的表示。这些内存区域可以是全局变量、栈上的局部变量或动态分配堆上的的变量。
- 细节丰富:抽象内存对象通常包含丰富的信息,数据类型、大小、生命周期等,以模拟程序对内存的实际使用。
符号(Symbol)
- 分析层次的抽象:符号(ValSym 或 ObjSym)是对这些内存区域或其他值(如临时值,寄存器等) 的进一步抽象。它们用于便于分析算法跟踪和理解值是如何在程序中流动
- 更高级的表示: 符号通常不包含与实际内存位置或布局相关的详细信息。它们更多地用于表示程序逻辑和控制流。
SVFIR or Program Assignment Graph (PAG)
SVF 将 LLVM 指令转换为图形表示形式,即PAG(Pointer Analysis Graph)。每一个PAGNode代表一个指针或者指针的地址取值变量,每条边(PAGEdge)代表两个指针之间的约束关系。
这里需要注意 PAG 与 ICFG 的不同之处:PAG 中每个顶点代表一个指针或指针的地址取值变量(ValSym 或 ObjSym),边代表两个 Sym 间的 Constraints;通常,在 ICFG 中,顶点更多地是用来表示程序中的一些特定点(如函数入口、函数退出、指令等,因此ICFG中的顶点可能包括两个 Sym 之间的 Constraints) ,而边用于表示控制流的转移。
PAG 是用于指针分析,而 ICFG 是用于表示程序的控制流。
PAGNode (SVFVar)
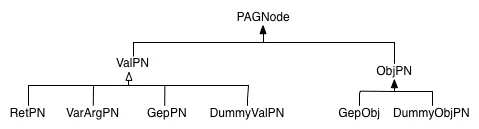
SVFVar 主要有两种类型:ValVar(ValPN)用于表示一个指针,而 ObjVar(ObjPN)用于表示一个抽象对象。GepObjVar(GepObjPN) 是 ObjVar(ObjPN) 的一个子类,用于表示一个聚合对象(如结构体或数组)的字段。GepValVar(GepValPN) 是 ValVar(ValPN) 的子类,用于表示一个引入的虚拟节点, 以便处理外部库调用 (例如,memcpy) 时实现字段敏感性,其中指向结构体字段的指针(LLVM 值)在指令中没有明确出现。
RetPN用于表示一个过程(函数或方法)唯一返回值。VarArgPN用于表示一个过程的可变参数
PAGEdge (SVFStmt)
我们将 PAGEdge 分为以下几类:
- AddrStmt (AddrPE):出现在内存分配点(Memory Allocation Site)(ValVar <– ObjVar)
- CopyStmt (CopyPE):出现在 PHINode、CastInst 或 SelectInst(ValVar <– ValVar)
- StoreStmt (StorePE):出现在 StoreInst(ValVar <– ValVar)
- LoadStmt (LoadPE):出现在 LoadInst(ValVar <– ValVar)
- GepStmt (GepPE) :出现在 GetElementPtrInst(ValVar <– ValVar)
- CallPE:从实际参数到形式参数(ValVar <– ValVar)
- RetPE:从 RetNode 到调用站点的返回值(ValVar <– ValVar)
SVFIRBuilder or PAGBuilder
- AllocaInst
- PHINode
- StoreInst
- LoadInst
- GetElementPtrInst
- CallInst
- InvokeInst
- ReturnInst
- CastInst
- SelectInst
- IntToPtrInst
- ExtractValueInst
- ConstantExpr
- GlobalValue
LLVM 中的所有其他指令都没有被处理,但它们也可以被转换为 PAG 中的基础边类型。
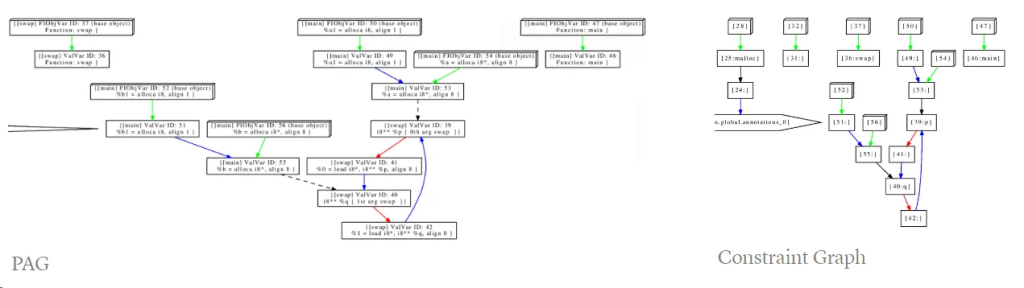
Constraint Graph
约束图(Constraint Graph)是基于包含关系的指针分析中PAG(Pointer Analysis Graph)的一个副本。PAG 作为一个基础图,用于在 SVF 的所有分析中表示整个程序,其边是固定的。然而ConstraintGraph 的边在约束解析过程中是可以改变的。
Pointer Analysis
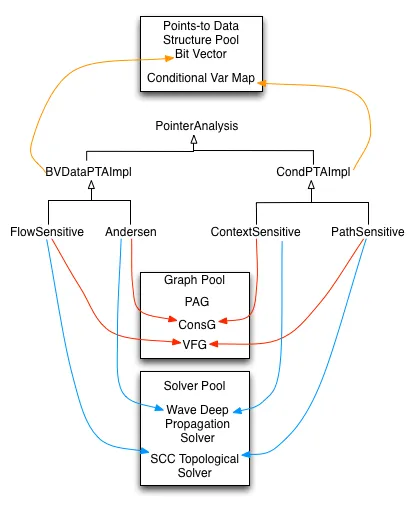
PointerAnalysis 是所有实现的根类。为实现不同的指针分析算法,用户可以基于不同的指向数据结构(PTData)选择不同实现。例如流敏感和流不敏感指针分析可以选择 BVDataPTAImpl 作为基础类,该类使用位向量作为其核心数据结构,以将指针映射到基于位向量的指向集合。一个需要上下文或路径条件作为每个指针前的限定符(Qualifier)的上下文-和路径敏感分析,可以选择 CondPTAImpl 作为其实现的选择。CondPTAImpl 将一个条件变量映射到其指向集合。
流敏感(Flow-sensitive)和流不敏感(Flow-insensitive)
- 流敏感分析: 在这种分析中,*代码的执行顺序(或控制流)*是重要的。分析会考虑指令之间相对顺序, 以更准确地模拟程序的行为。 通常会得到更精确的结果, 但计算成本也更高。
- 流不敏感分析: 在这种分析中,代码的执行顺序不是重要的。 所有指令都被一视同仁,不考虑它们的执行顺序。这种分析通常更快,但可能不如流敏感分析精确。
上下文敏感(Context-sensitive)和上下文不敏感(Context-insensitive)
- 上下文敏感分析: 这种分析考虑函数或过程的调用上下文。 也就是说,同一个函数在不同的调用上下文中可能有不同的行为。这通常会得到更精确的结果,但计算成本也更高。
- 上下文不敏感分析: 这种分析不考虑函数或过程的调用上下文。 每个函数只分析一次,假设它在所有调用上下文中行为都是相同的。 这种分析更快, 但是不如上下文敏感分析精确。
路径敏感(Path-sensitive)和路径不敏感(Path-insensitive)
- 路径敏感分析: 这种分析考虑到从程序的入口到一个特定点的所有可能的执行路径。 这通常会得到更精确的结果,但由于需要考虑多个路径,计算成本也更高。
- 路径不敏感分析: 这种分析不考虑具体的执行路径。 它通常只关心在达到某个点之前哪些操作是可能的,而不是这些操作是如何组织在一起的。
为什么存在 CondPTAImpl?
- 上下文敏感性:在某些情况下,仅仅考虑指令的执行顺序(即流敏感或流不敏感)是不够的。有时还需要考虑函数调用的上下文。例如,同一个函数在不同的调用上下文中可能有不同的行为。
- 路径敏感性:类似地,考虑从程序开始到特定点的所有可能路径(路径敏感性)可能也是必要的。
- 复杂约束:有时,指针的行为可能依赖于某些条件或变量的值。
CondPTAImpl可以用于处理这种类型的复杂约束。不同维度的分类
- 流敏感/流不敏感:主要关注的是代码的线性执行顺序。
- 上下文敏感/上下文不敏感:主要关注的是函数调用的嵌套结构和作用域。
- 路径敏感/路径不敏感:主要关注的是代码中的分支和循环结构。
因此,尽管流敏感和流不敏感的指针分析是非常常用的分类,但它们并不涵盖所有可能的指针分析类型。其他的分类维度(如上下文敏感性和路径敏感性)也是非常重要的,特别是在需要更高精度的场景中。这就是为什么除
BVDataPTAImpl之外,还需要CondPTAImpl这样的其他实现的原因。
每种指针分析实现都基于图表示法,并使用求解器来解决约束问题。例如,Andersen的分析可以通过选择一个合适的求解器来轻松编写, 该求解器用于在基于包含的约束图(ConsG)上推导出传递闭包规则。 同样地, 流敏感分析可以通过遵循流敏感的强 / 弱更新规则以及在稀疏值流图(VFG)上的指向传播求解器来实现。
Andersen’s Algorithm:针对 C 编程语言的高效的程序间指针分析方法。该分析对每一个指针类型的变量,在程序执行过程中,近似地确定它可能指向的对象集合。 这些信息可以用来提高其他分析的准确性。
仅考虑了指针所指向的对象,没有考虑解引用的指针所指向的对象

Andersen’s Pointer Analysis
Andersen 的指针分析属于基于包含(inclusion-based)的分析。在这种类型的分析中,指针变量的“指向集合”(points-to set)是通过解决一组包含关系(inclusion constraints)来推导的。具体来说,如果有一个约束 p⊆q,这意味着所有 p可能指向的对象也都是 q可能指向的对象。Andersen 的分析会生成这样一组包含约束,并通过求解这些约束来确定每个指针变量的指向集合。
Release/bin/wpa -nander -print-pts swap.ll可用于打印指向关系。
指向关系可以根据其创建方式被分类为静态或动态。在一个数组int a[10]的情况下,名称a 静态地指向代表数组内容的对象。此外,当适当地转换时,一个指向结构体指针指向该结构体的初始成员(依据 ISO C 标准)。准确的静态指向信息可以在程序的单次遍历中收集。
程序执行过程中创建的指向关系被称为动态。例如,p = x创建了一个 p 和 x 之间的指向关系,alloc 调用返回一个指向对象的指针,以及 strdup 返回一个指向字符串的指针。更通用的值设置函数也可能创建一个动态的指向关系。


Andersen‘s 分析是针对 C 的流不敏感(flow-insentitive)、上下文敏感、基于约束的指向分析.
流不敏感(flow-insentitive)和流敏感分析(flow-sentitive) 的概念与程序点特定(program-point specific)与摘要(summary) 分析的概念密切相关。如果一个分析为每个程序点计算指向信息,那么这种分析被称为程序点特定的分析。那些为函数中所有程序点或全局变量维护一个摘要的分析被称为摘要分析。流敏感分析必然是程序点特定的。

Poor Man’s Program-point Analysis
“穷人版”的流敏感分析方法是轻量级或简化版的程序点特定分析方法。与完全程序点特定分析(在程序的每个点进行详细分析)相比,这种方法试图以更低的计算成本获取相似的准确性。
Intra- and Inter-procedural Analysis

Intra-procedural分析是指函数是在上下文无关的情况下进行分析的;Inter-procedural分析是在考虑调用上下文的情况下推断信息的。Intra-procedural分析也被称为单变量(monovariant)或粘性(sticky),Inter-procedural分析也被称为多变量(polyvariant)。
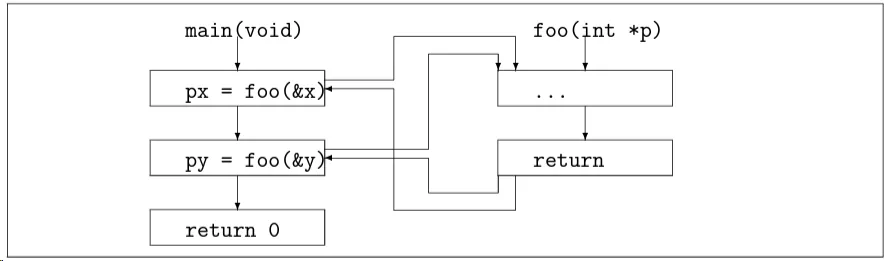
Pointer Analysis Of C

实际上在标准C语言实现中,多个结构体变量共享相同的类型定义(例如都是
struct S)通常并不会被赋予不同的名称。它们都会有相同的类型struct S。在这种情况下,这些变量(例如s,t,u)是类型兼容的,因此可以互相赋值。然而,在某些特殊的静态分析或者编译器优化上下文中,可以选择为这些变量赋予不同的类型标签或类型变种。这样做主要是为了提高分析的精度或进行更细粒度的优化。通过为具有相同结构体类型但用于不同上下文的变量赋予不同的类型标签,分析或优化可更准确地理解这些变量的行为和相互作用。
例如,在你给出的例子中(值流分析的上下文), 这种“类型重命名”被用来跟踪不同变量(
s和t)如何“流动”到一起。一旦确定了这一点,分析就可以合并这些类型,从而更准确地表示程序的行为。这并不是 C 语言本身的特性,而是特定分析或优化方法选择采用的一种策略。
不同类型的结构体变量不能一起流动(flow together)。相同类型的结构体变量可以一起流动:
对于结构体变量的字段成员的指向信息,与结构体的定义而非结构体对象相关联。例如,对于成员s.p(假设使用上面的例子中的定义),其指向信息用S1.p表示,其中S1是struct S1的定义。这个定义对该类型的所有对象是通用的。因此:在执行t = s这样的赋值操作时,不需要针对s更新t的字段——值流分析已经处理了这一点。
因此,指针分析被分解为两个子分析:
- (结构体)值流分析;2. 指向传播分析
Implementation-defined Features

“A pointer with less alignment requirement”意味着该指针指向数据类型有更宽松的对齐限制。

假设未知的指针在赋值的左侧不会被解引用。
Separate Translation Units
这篇论文的工作仅考虑单一的整体程序(例如,一个模块或一个文件)。
Safe Pointer Abstraction
Abstraction Location
例如,如果一个指针$p$运行时可能包含位置$l_x$(即$x$的位置)和$l_g$(即$g$的位置),一个安全的抽象(Safe Pointer Abstraction)表示是$p↦\\{l_x,l_g\\}$。

抽象位置集合 ALoc (关键概念)是按照如下的递归方式定义的:
- 如果 v 是全局变量的名字:v ∈ ALoc。
- 如果 v 是某个有 n 种变体【不同执行路径或上下文】的函数的参数:$v_i$ ∈ ALoc,i=1,…,n。
- 如果 v 是某个有 n 种变体的函数的局部变量:$v_i$ ∈ ALoc,i = 1, … , n。
- 如果 s 是一个字符串常量:s ∈ ALoc。
- 如果 f 是有 n 种变体的函数【归函数上施加了1-limit】的名字:$f_i$ ∈ ALoc,其中 i=1,…,n。
- 如果 f 是有 n 种变体的函数的名字:$f_i^0$【表示函数抽象返回位置】∈ALoc,其中i=1,…,n。
- 如果 l 是有 n 种变体的函数中的一个分配(alloc)标签:$l_i$ ∈ ALoc,其中 i = 1,…,n。
- 如果 l 是有 n 种变体的函数中的一个地址操作符(address operator)标签:$l_i$ ∈ ALoc。
- 如果 o∈ALoc表示一个“数组”类型的对象:o[] ∈ ALoc。
- 如果 S 是结构体或联合体类型的类型名:S ∈ ALoc。
- 如果 S∈ALoc 是“结构体”或“联合体”类型:对于 S 的所有字段 i,S.i ∈ ALoc。
- Unknown ∈ ALoc。
所有的数组元素被合并为一个整体。具有相同名称的结构体对象的字段也会被合并。例如,给定定义 truct S { int x; } s, t;,字段 s.x 和 t.x 会被合并(或称为折叠,前面提及)。
如果 f 是一个函数标识符,我们用 $f:x_i$ 表示 f 的参数 $x_i$。
Pointer Abstraction
定义 4.3:一个满足以下条件的指针抽象 $\widetilde{S}$ : ALoc→P(ALoc):
- 如果 o ∈ ALoc 是基础类型:$\widetilde{S}$(o) = {Unknown}。
- 如果 s ∈ ALoc 是结构体/联合体类型:$\widetilde{S}$(s) = {}。
- 如果 f ∈ ALoc 是函数指示符:$\widetilde{S}$(f) = {}。
- 如果 a∈ ALoc 是数组类型:$\widetilde{S}$(a)={a[]}。
- $\widetilde{S}$(Unknown) = Unknown。
第一个条件要求基础类型的对象由Unknown抽象。这是因为该值可能被转换为一个指针,因此通常是未知的。 第二个条件规定一个结构体对象的抽象值是空集。注意结构体对象是由其类型唯一确定的。第四个条件要求数组变量指向其内容。最后,未知位置的内容是未知的。
定义:s ∈ ALoc\{Unknown} : {s} ⊆ {Unknown}。
Safe Pointer Abstraction
直观地说,如果一个程序的指针抽象能捕获在运行时一个指针可能指向的所有对象,那么这个指针抽象就是安全的。
定义一个显而易见的抽象函数 $\alpha$:Loc→ALoc。例如,如果$l_x$是函数$f$ 第*i*个变体(variant)中参数x位置,那么$\alpha(l_x)=x_i$。从初始程序点 $p_0$和初始程序存储$S_0$出发的执行路径表示为

其中$S_n$是程序点$p_n$处的存储(Store)。
设p是一个程序,$S_0$ 是一个初始存储(将程序输入映射到目标函数的参数)。设 $p_n$是一个程序点,$L_n$是所有可见变量的位置。一个指针抽象$\widetilde{S}$相对于$p$是安全的,如果

每个程序都有安全的指针抽象。定义$\widetilde{S}_{triv}$以满足定义,并将其扩展,使得对于所有o∈ALoc,其中o是指针类型,$\widetilde{S}_{triv}$={Unknown}。显然,这是一个安全的——但无用的——抽象。


Pointer analysis specification
Types and Programming Languages
Value-Flow Construction
Analyze a Simple C Program
截止目前
LLVM – 编译安装 编译版本合适的 LLVM + Clang(使用新版本的 LLVM 会导致问题)
An Example
SVF is a static value-flow analysis tool for LLVM-based languages. SVF (CC’16) is able to perform
- WPA (whole program analysis): field-sensitive (SAS’19), flow-sensitive (CGO’21, OOPSLA’21) analysis;
- DDA (demand-driven analysis): flow-sensitive, context-sensitive points-to analysis (FSE’16, TSE’18);
- MSSA (memory SSA form construction): memory regions, side-effects, SSA form (JSS’18);
- SABER (memory error checking): memory leaks and double-frees (ISSTA’12, TSE’14, ICSE’18);
- MTA (analysis of multithreaded programs): value-flows for multithreaded programs (CGO’16);
- CFL (context-free-reachability analysis): standard CFL solver, graph and grammar (OOPSLA’22, PLDI’23);
- SVFIR and MemoryModel (SVFIR): SVFIR, memory abstraction and points-to data structure (SAS’21);
- Graphs: generating a variety of graphs, including call graph, ICFG, class hierarchy graph, constraint graph, value-flow graph for static analyses and code embedding (OOPSLA’20, TOSEM’21)
通过一个例子来逐一介绍 SVF 的各个组成部分:
(1)内存模型,包括PAG(程序分析图)和约束图;
(2)指针分析,包括流不敏感和流敏感分析,以及;
(3)值流构建(Value-Flow Construction)。
C Code
void swap(char **p, char **q)
{
char* t = *p;
*p = *q;
*q = t;
}
int main()
{
char a1, b1;
char *a = &a1;
char *b = &b1;
swap(&a,&b);
}LLVM IR after the mem2Reg option is turned on (A project or a C file can also be compiled to generate bc using wllvm)
llvm-project-13.0.0.src/build/bin/clang -S -c -Xclang -disable-O0-optnone -fno-discard-value-names -emit-llvm swap.c -o swap.ll
llvm-project-13.0.0.src/build/bin/opt -S -mem2reg swap.ll -o swap.llclang: LLVM 项目的 C/C++/Objective-C 编译器。
-S: 仅运行预处理和编译步骤。
-c: 仅运行预处理、编译和汇编步骤。
-cc1: 内部命令,接收预处理过的C文件并将其转为汇编代码,是实际进行C语言编译的部分
-Xclang <arg>: 将<arg>传给clang -cc1。
-Xclang -disable-O0-optnone: 禁用在 O0 的优化级别下向函数添加 optnone 属性;如果没有
-Xclang -disable-O0-optnone 选项,opt无法对 IR 进行优化。
-fno-discard-value-names: 在 LLVM IR 中不要丢弃值名称。
-emit-llvm: 使用 LLVM 表示用于汇编和目标文件。
opt: LLVM 的优化工具,用于对 LLVM IR 进行各种转换和优化。
-S: 表示输出为 LLVM 汇编形式
-passes='-mem2reg': 指定运行哪些优化或转换通道(passes)。在这里,-mem2reg是一个将内存访问(如 alloca,load,和 store 指令)转换为寄存器访问的优化通道。
; ModuleID = 'swap.ll'
source_filename = "swap.c"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
; Function Attrs: noinline nounwind uwtable
define dso_local void @swap(i8** %p, i8** %q) #0 {
entry:
%0 = load i8*, i8** %p, align 8
%1 = load i8*, i8** %q, align 8
store i8* %1, i8** %p, align 8
store i8* %0, i8** %q, align 8
ret void
}
; Function Attrs: noinline nounwind uwtable
define dso_local i32 @main() #0 {
entry:
%a1 = alloca i8, align 1
%b1 = alloca i8, align 1
%a = alloca i8*, align 8
%b = alloca i8*, align 8
store i8* %a1, i8** %a, align 8
store i8* %b1, i8** %b, align 8
call void @swap(i8** %a, i8** %b)
ret i32 0
}
attributes #0 = { noinline nounwind uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2}
!llvm.ident = !{!3}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 1}
!2 = !{i32 7, !"frame-pointer", i32 2}
!3 = !{!"clang version 13.0.0 (<https://github.com/SVF-tools/SVF.git> 5fce6716cd279b42ef8ab3f6f6d0a1a413d70b97)"}Call Graph
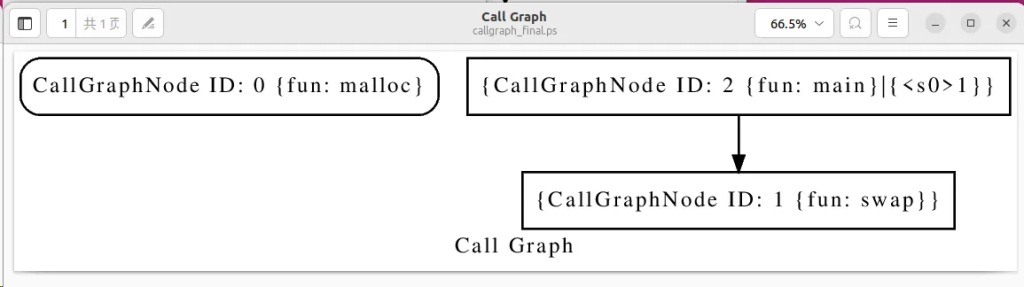
Release-build/bin/wpa -ander -dump-callgraph swap.ll
输出一些信息并得到callgraph_initial.dot和callgraph_final.dot两个文件。
sudo apt install graphviz
dot -Tps callgraph_inital.dot -o callgraph_initial.ps
dot -Tps callgraph_final.dot -o callgraph_final.ps
open callgraph_initial.ps
open callgraph_final.ps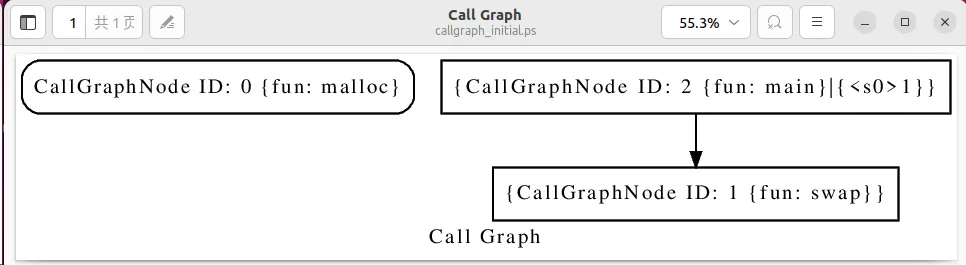
Interprocedural Control-Flow Graph
Release-build/bin/wpa -type -dump-icfg swap.ll
dot -Tps icfg_initial.dot -o icfg_initial.ps
dot -Tps icfg_final.dot -o icfg_final.ps
open icfg_initial.ps
open icfg_final.psGlobalICFG Node0 或者通常表示为 Node0 是通常用来表示程序的全局入口或起始点。它通常不对应于任何实际的代码行,而是作为图中所有全局初始化和全局作用域代码(如全局变量初始化,静态构造函数等)的逻辑起始点。
具体来说,Node0 可能执行以下几种作用:
- 全局初始化的起点:所有的全局变量或静态变量的初始化都可以从这个节点开始。
- 程序入口点:主函数(比如C/C++中的
main函数) 从这个节点可达。 - 链接其他函数:通过这个节点,其他的函数(包括库函数)可能被链接或者调用。
- 作为分析的起点:在程序分析中,从这个节点开始可以进行各种静态或动态分析。

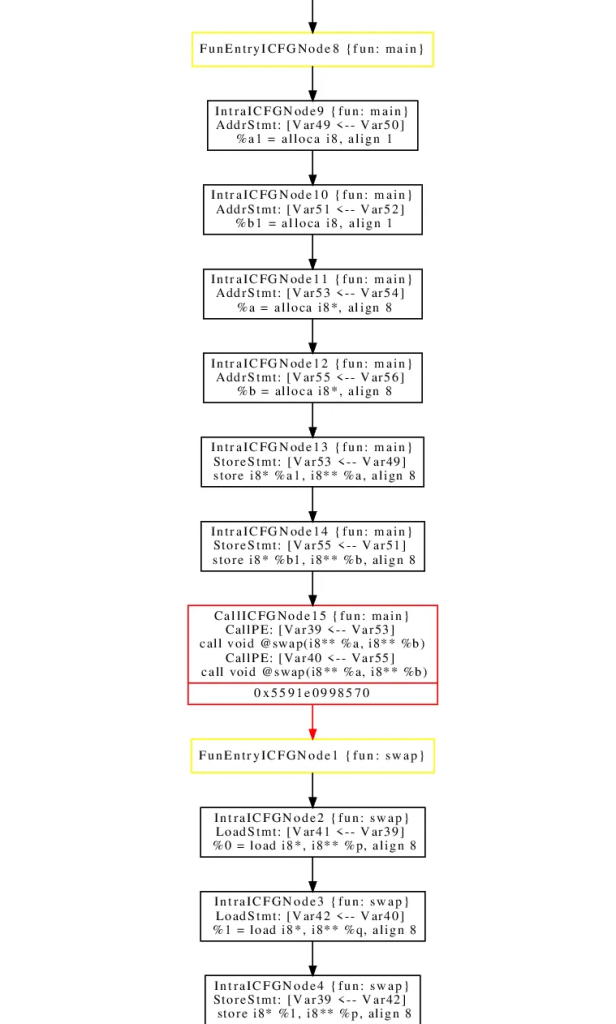
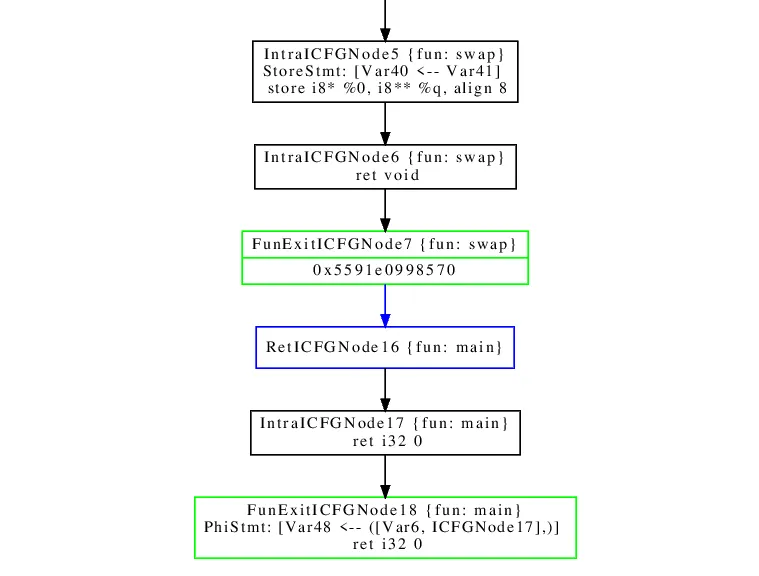
FunEntryICFGNode(或称为函数入口 ICFG 节点)通常用于表示某个特定函数或方法的入口,这个节点成为 ICFG 中该函数所有可能执行路径的起始点。当控制流进入这个函数时,它会首先经过这个节点。
IntraICFGNode(或者称为“程序内部ICFG节点”)通常用于表示单个函数(或过程)内部的某一控制流节点。这与 FunEntryICFGNode(函数的入口节点)和 FunExitICFGNode(函数出口节点)不同,后两者用于标识函数的开始和结束。
FunExitICFGNode(或函数退出 ICFG节点)通常用于表示一个函数(或过程)的退出点。这个节点是函数控制流的结束标志,并可能与函数的返回值或 return 语句相关联。
RetICFGNode(或称为返回 ICFG节点)通常用于表示一个函数(或过程)中的 return 语句或等效的退出机制。
Program Assignment Graph (PAG)
Release-build/bin/wpa -nander -dump-pag swap.ll
dot -Tps svfir_initial.dot -o svfir_initial.ps
open svfir_initial.ps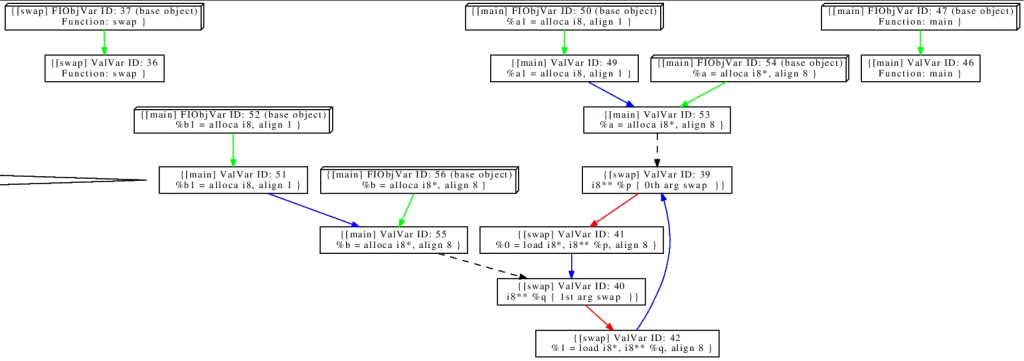
Value-Flow Graph
程序的跨过程稀疏值流图(SVFG)是有向图,它捕获了顶级指针和取地址对象的 def-use 链。