Transformers 架构
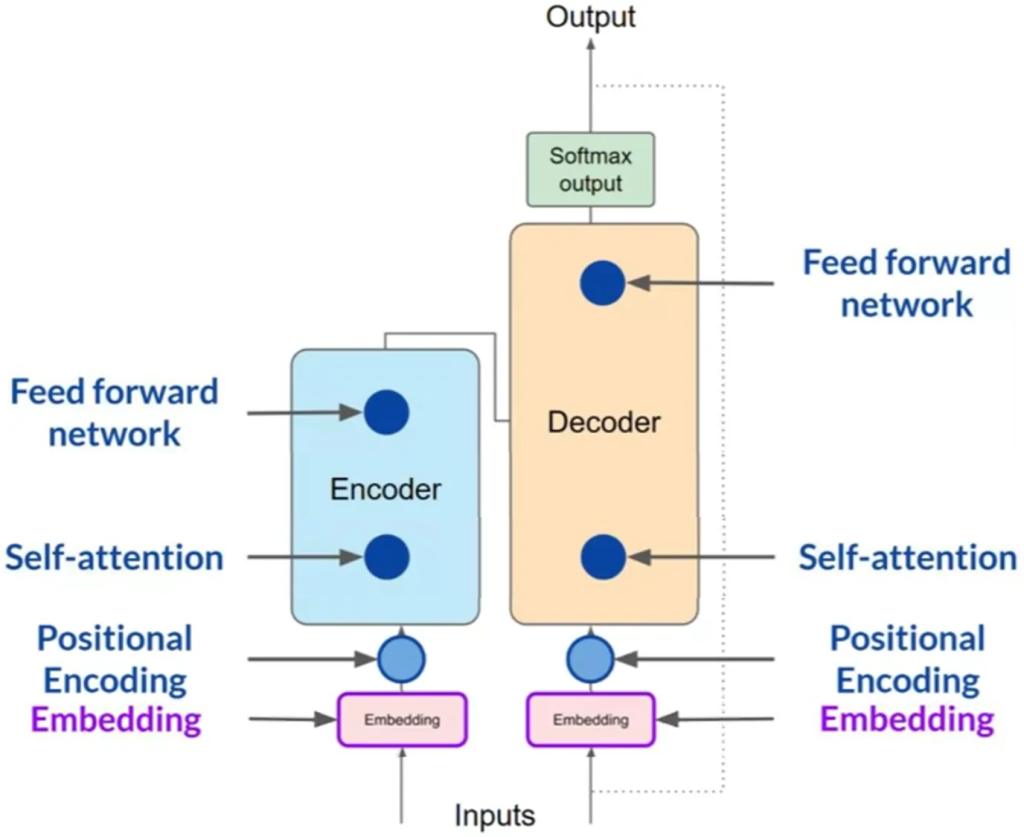
Transformers architecture
自注意力机制(Self-Attention): Transformers的核心在于自注意力机制,它能够学习句子中所有词汇的相关性和上下文,不仅关注相邻词, 还关注句子任何其他词汇.
Transformers与RNNs比较:Transformers架构在自然语言处理任务上显著优于早期的循环神经网络(RNNs),引领了一场在生成能力上的革新.
注意力权重:这些注意力权重在训练过程中被学习,使模型能够理解每个词与句子中其他词的关系,从而更好地把握语言结构。
Transformers的两部分结构:Transformers架构分为编码器和解码器两部分,这两部分共享许多相似之处。
文本的数字化处理:模型通过数字而非文字工作,因此需要将文本分词(Tokenization),将每个词转换成数字(即词在字典中的位置)。
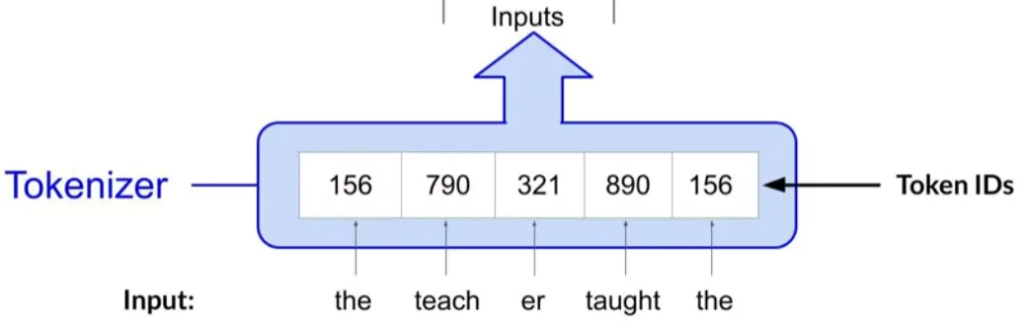
Tokenization
嵌入层(Embedding Layer):Token ID会被映射到高维向量空间中的一个向量。 每个词汇在这个空间中占据唯一的位置,这些向量旨在编码输入序列中个别词汇的意义和上下文。
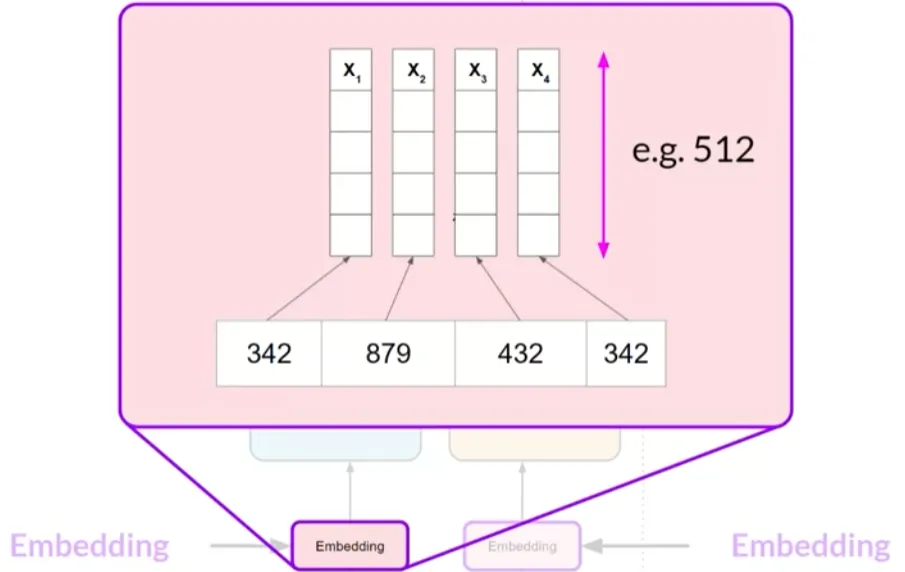
嵌入层(Embedding Layer)
位置编码(Positional Encoding):由于模型并行处理每个输入标记,位置编码用于保留词汇顺序信息,确保不丢失词汇在句子中的位置相关性。
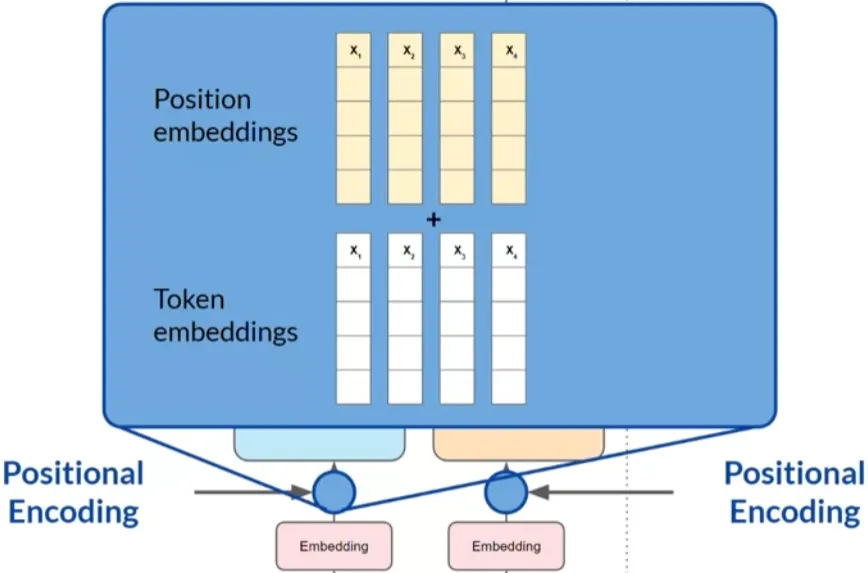
位置编码(Positional Encoding)
自注意力层(Self-Attention Layer):这一层分析输入序列中各个标记之间的关系。通过训练学习的自注意力权重反映了输入序列中每个词对其他所有词的重要性。
多头自注意力(Multi-Headed Self-Attention):Transformer架构实际上包含多个自注意力头,这些头并行独立地学习,每个头可能学习语言的不同方面。
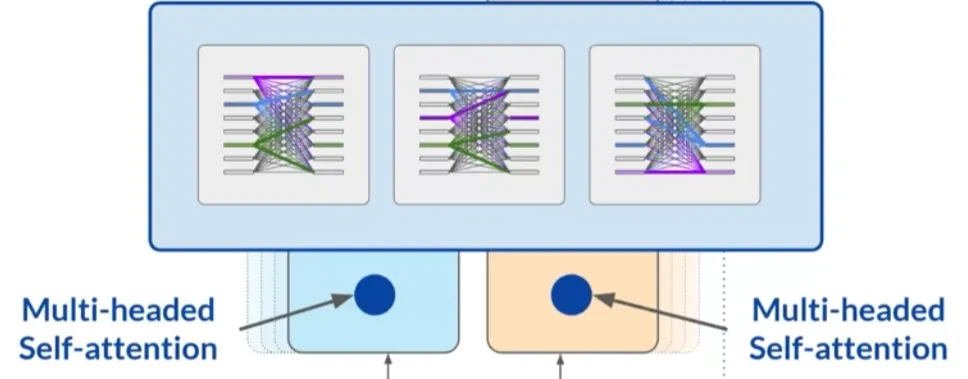
多头自注意力(Multi-Headed Self-Attention)
全连接前馈网络:注意力权重应用到输入数据后,输出数据会通过一个全连接前馈网络,该层的输出是与分词字典中每个词相对应的概率分数的向量。
Softmax层:这些概率分数通过Softmax层标准化,最终生成每个词的概率分数,从而模型可以预测出下一个最可能的词汇。
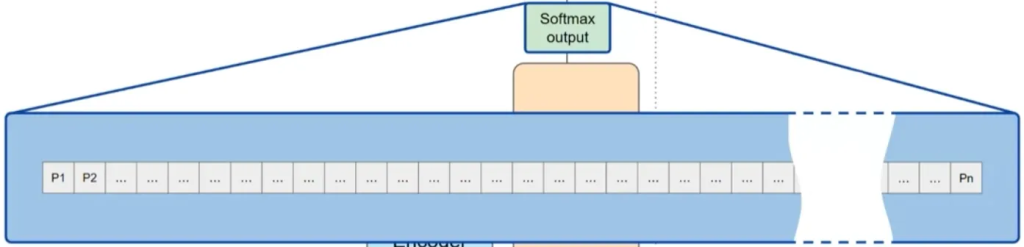
Softmax层